Industrial robots take hours to program but perform quickly, tirelessly, and precisely without human intervention once programmed. Mobile robots are teleoperated, can attempt tasks immediately, but are imprecise, ungainly, and keep a human operator effectively tethered to the system at all times. As mobile robots become more complex with more degrees-of-freedom and greater mission space, the burden on the operator becomes even more taxing. Visual Targeting is a technology that bridges this gap. It provides a means where the operator defines objects of interest in the environment via camera systems while motion planners automatically generate the robot trajectories to achieve the goal.
Need
Mobile manipulator systems are deployed to the nastiest places: ground zero, Fukushima, methlabs, ordinance disposal sites, and to the booby-trapped labs of anarchists. In war zones the operator is at risk since the enemy is aware that for every robot, there is a man linked to the controls. Visual targeting is a technology aimed at reducing the robot operator’s cognitive burden while performing tasks more quickly and elegantly. The operator is needed to develop plans of action for the robot, but by converting mouse clicks on imagery into automated motion, visual targeting can dramatically reduce the stick time.
Challenge
The challenge for adding autonomy to mobile robots is being able to plan semi-autonomous motions when given only partial information.
To achieve full autonomy, a robot manipulator motion planner would need complete information before it could define a safe path. It would need to know the location of every possible object in the workspace that might impede robot motion and would need a sophisticated grasp planner that could match target geometry to gripper surfaces. Unfortunately, acquiring this level of detail in a robot system is expensive and time consuming and is impractical for most remote emergency response robotic deployments.
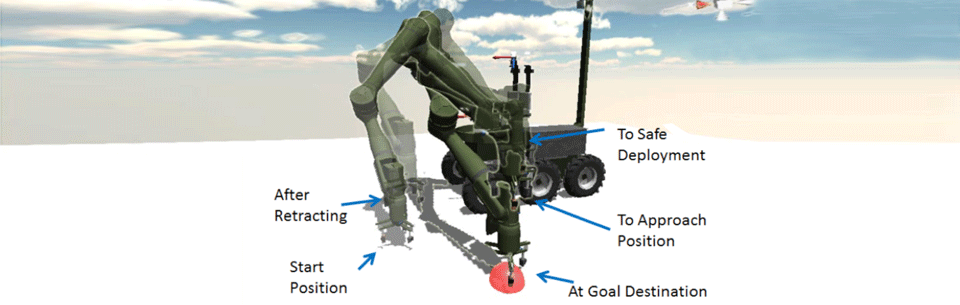
Visual Targeting presents a compromise between pure teleoperation and full autonomy. Only the pertinent destination features are provided and the planner takes a “best guess” approach to computing the robot motion. For instance, in a “Move above” behavior, only a single pair correspondence must be created to define a single 3-D point in space. The planner then determines a motion plan that moves from the current location to a point immediately above the target with a rotation reference frame pointed down and with a safe stand-off distance. All motion is executed within a monitored supervisory mode and it is the operator’s responsibility to ensure that the planned motion doesn’t result in unplanned collisions. If the “best guess” planner fails, the operator either halts play and creates a new plan or takes over in teleoperation mode.
Solution

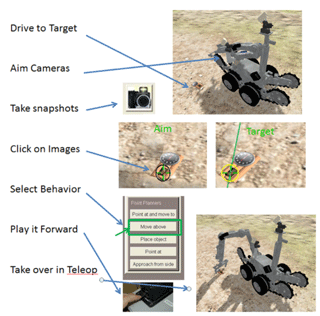
Visual Targeting has been developed and refined at Sandia over the last decade and is described initially in a U.S. patent1 but has continued to evolve over time. Targeting uses triangulation data from a pair of video cameras pointing at a target to define points in space. The operator chooses an action which invokes a motion planner acting upon the location data and then drives the remote robot vehicle accordingly. It combines what the human operator is able to do — analyze complex video scenes, identify features of interest, and determine courses of action — with what the camera and robot system can do — accurately measure positions and offsets and plan compatible manipulator motion paths.
The operator defines features of interest taken from video snapshots of the robot’s environment using either a mouse or a touchscreen. By identifying a single feature in two images, a 3-D point can be defined; by identifying two pairs of correspondences a line can be defined; and with three feature pairs a surface can be described. The art of visual targeting is in the integration — developing a system in which the operator will perform additional operations, use more hardware, and yet still feel that the task is simpler.
1 Controlling Motion Using a Human Machine Interface: http://www.google.com/patents/US7802193