A Sandia-developed benchmark re-ranks the top computers
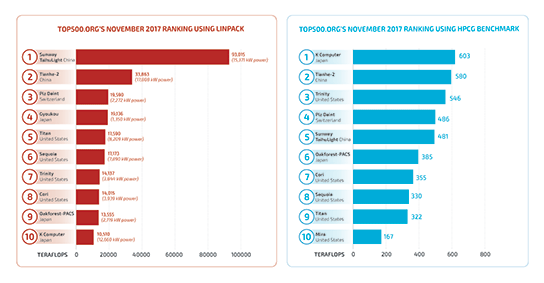
A Sandia software program now installed as an additional test for the widely observed Top500 supercomputer challenge has become increasingly prominent. The program’s full name — High Performance Computing Gradients, or HPCG — doesn’t come trippingly to the tongue, but word is seeping out that this relatively new benchmarking program is becoming as valuable as its venerable partner — the High Performance Linpack program — which some say has become less than satisfactory in measuring many of today’s computational challenges.

“HPL used to represent a broad spectrum of the core computations that needed to be performed, but things have changed,” says Sandia researcher Mike Heroux, who originated and developed the HPCG program. “Linpack performs compute-rich algorithms on dense data structures to identify the theoretical maximum speed of a supercomputer. Today’s applications often use sparse data structures, and computations are leaner.”
The term “sparse” means that a matrix under consideration has mostly zero values. “The world is really sparse at large sizes,” says Mike. “Think about your social media connections: there may be millions of people represented in a matrix, but your row — the people who influence you — are few. So, the effective matrix is sparse. Do other people on the planet still influence you? Yes, but through people close to you.”
Similarly, for a scientific problem whose solution requires billions of equations, most of the matrix coefficients are zero. For example, when measuring pressure differentials in a 3-D mesh, the pressure on each node is directly dependent on its neighbors’ pressures. The pressure in faraway places is represented through the node’s near neighbors. “The cost of storing all matrix terms, as Linpack does, becomes prohibitive, and the computational cost even more so,” says Mike. A computer may be very fast in computing with dense matrices, and thus score highly on the Linpack test, but in practical terms the HPCG test is more realistic, Mike says.
To better reflect the practical elements of current supercomputing application programs, Mike developed HPCG’s preconditioned iterative method for solving systems containing billions of linear equations and billions of unknowns. “Iterative” means that the program starts with an initial guess to the solution, and then computes a sequence of improved answers. Preconditioning uses other properties of the problem to quickly converge to an acceptably close answer.
Companies embrace new benchmark
“To address the problems we need to solve for our mission, which might range from a full weapons simulation to an National Renewable Energy Laboratory windfarm, we need to describe physical phenomena to high fidelity, such as the pressure differential of a fluid flow simulation. For a mesh in a 3-D domain, you need to know at each node on the grid the relations to values at all the other nodes. A preconditioner makes the iterative method converge more quickly, so a multigrid preconditioner is applied to the method at each iteration.”
Supercomputer vendors like NVIDIA, Fujitsu, IBM, Intel, and Chinese companies write versions of HPCG’s program that are optimal for their platform. While it might seem odd for students to modify a test to suit themselves, it’s clearly desirable for supercomputers of various designs to customize the test, as long as each competitor touches all the agreed-upon calculation bases. “We have checks in the code to detect optimizations that are not permitted under published benchmark policy,” says Mike.
On the HPCG Top500 list, the Sandia/Los Alamos supercomputer Trinity has risen to number 3, and is the top DOE system. Trinity is number 7 overall in the Linpack ranking. HPCG better reflects the Trinity design choices.
Mike says he wrote the base HPCG code 15 years ago, originally as a teaching code for students and colleagues who wanted to learn the anatomy of an application that uses scalable sparse solvers. Jack Dongarra and Piotr Luszczek of the University of Tennessee have been essential collaborators on the HPCG project.
In particular, Jack, whose visibility in the HPC community is unrivaled, has been a strong promoter of HPCG. “His promotional contributions are essential,” says Mike. “People respect Jack’s knowledge and it helped immensely in spreading the word. But if the program wasn’t solid, promotion alone wouldn’t be enough.”
Mike invested his time in developing HPCG because he had a strong desire to better ensure the US stockpile’s safety and effectiveness. The supercomputing community needed a new benchmark that better reflected the needs of the national security scientific computing community, he says.
“I had worked at Cray for 10 years before joining Sandia in ’98,” he says, “when I saw the algorithmic work I cared about moving to the labs for the Accelerated Strategic Computing Initiative (ASCI). When the US decided to observe the no-nuke-test treaty, we needed high-end computing to better ensure the stockpile’s safety and effectiveness. I thought it was a noble thing, that I would be happy to be part of it, and that my expertise could be applied to develop next-generation simulation capabilities. ASCI was the big new project in the late 1990s, if you wanted to do something meaningful in my area of research and development.”
Mike is now director of software technology for DOE’s Exascale Computing Project. There, he works to harmonize the computing work of the DOE national labs — Oak Ridge, Argonne, Lawrence Berkeley, Pacific Northwest, Brookhaven, and Fermi, along with the three NNSA defense labs.
“We have an opportunity to create an integrated effort among the national labs,” Mike says. “We now have daily forums at the project level, and the people I work with most closely are people from the other labs. Because ECP is integrated, we have to deliver software to the applications and the hardware at all labs. DOE’s attempt at a multi-lab project gives an organizational structure for us to work together as a cohesive unit so that software is delivered to fit the key DOE applications.”
Among Mike’s achievements, he served for six years as editor-in-chief of ACM’s Transactions on Mathematical Software, and is a senior scientist at Sandia.