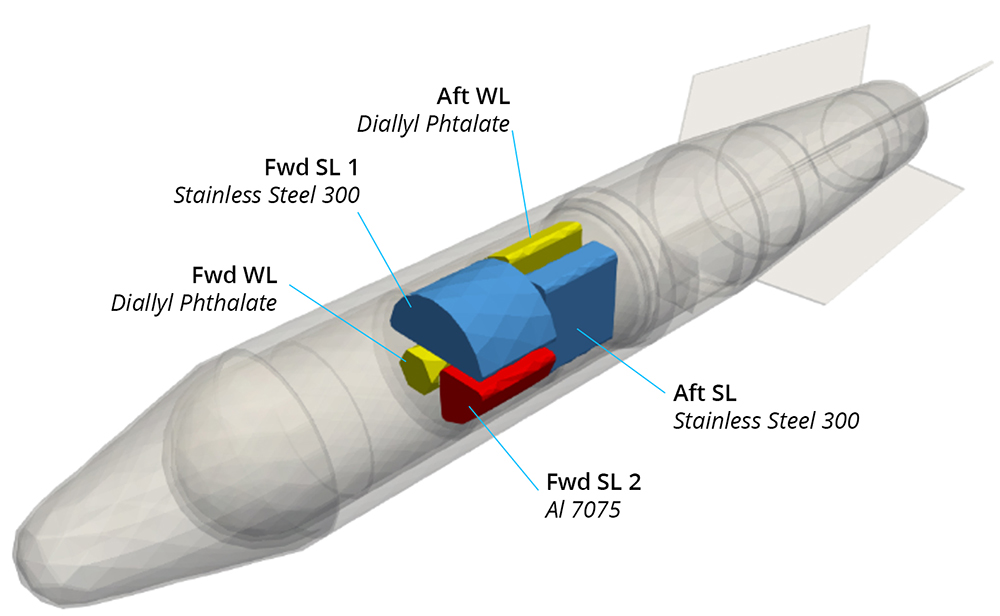
Modern aerospace design blends a multidisciplinary set of engineering and physics tools with computational simulation to achieve the design requirements for a given vehicle. One such requirement is thermal safety, in which it is paramount to anticipate critical weakness thresholds for various machine parts to ensure they are manufactured to satisfy operational requirements. A crucial component of this design process is analyzing scenarios in which the design body becomes engulfed by a fire and intense amounts of heat are radiated throughout the system. To ensure the device does not malfunction, units called links are installed; these links typically come in pairs, one stronglink and one weaklink. Embedded within the engineering design is the assumption that the weaklink will reach its critical failure temperature before the stronglink (see Figure 1), thereby preventing the design from malfunctioning.
For a given thermal load scenario, the competing occurrences of the links’ failure modes constitute what is known as a “thermal race.” The success or failure of each potential thermal race traces out a decision boundary in the design parameter space. One can think of decision boundaries as dividing regions in space; on one side of the boundary, the designs are acceptable, whereas the opposite side results in a failed system. However, due to the chaotic nature of fires, it is impossible to simulate every possible combination of directions and heat intensities that may be encountered. These types of simulations are computationally expensive due to the high-dimensional nature introduced by material, geometric and environmental parameters. Any brute-force algorithm which attempts to find this decision boundary by discretizing the design space is therefore intractable and necessitates the use of adaptive learning algorithms to find these failure thresholds.
The Fusion of Simulation, Experiments and Data (FuSED) team has developed a decision boundary tool that complements the HPC environments by leveraging a machine-learning classification algorithm known as support vector machines (SVMs). This algorithm has two steps: (1) training a surrogate model using adaptive-learning SVMs that approximate the high-fidelity model of interest, and (2) using a post-processing step that calculates the probability that a certain design will exceed the designated threshold.
Training the surrogate is done by iteratively selecting points in the parameter space, which will yield information about the location of the decision boundary. Once a convergence criterion has been reached, the training step concludes and engineers can then query the surrogate as a proxy for the high-fidelity model and gain a computationally inexpensive estimate of whether parameter values will lead to an acceptable design. In general, there are two types of parameters that need to be considered: deterministic and uncertain. The deterministic parameters are concrete design options in the model that engineers have the capability of controlling. In contrast, the uncertain variables account for randomness in the system.
Sandia’s novel approach trains the surrogate model over both deterministic and uncertain variables. The advantage is that once the surrogate is trained, a simple post-processing step can calculate the probability that a particular combination of design parameters will exceed the specified threshold. In this sense, the result is condensed down to the dimensionality of just the design space parameters while simultaneously adding parametric uncertainty into the model. One added difficulty of training surrogates over this combined space is that the dimensionality of the inputs increases. In general, many algorithms suffer from the curse of dimensionality but by leveraging SVMs, the team can ameliorate the issue and avoid the exponential growth in training data that is typically required. Details regarding this approach can be found in a recently published article in Structural and Multidisciplinary Optimization entitled “Assessing decision boundaries under uncertainty.”
One core feature that was added to the algorithm is a concept referred to as “iteration concurrency.” Due to the iterative nature of training the surrogate model, each step of training depends on the training points prior to that step. This typically precludes one from parallelizing the iterations since one must know the results of the current step to proceed forward. Iteration concurrency is a way to perform multiple training steps simultaneously by calculating hypothetical results. Since there are only a finite number of possible results from each step, the algorithm can suggest which points to train on, given every possible result. By calculating these simulations in parallel, two iterations of training can be executed concurrently. Once the simulations have finished, the model is trained on the actual results and the extraneous information is discarded. In this sense, the amount of time one must wait for the entire training phase to occur is cut in half. Depending on the available computational resources, the iteration concurrency can be performed on as many steps as desired, yielding further time reductions.
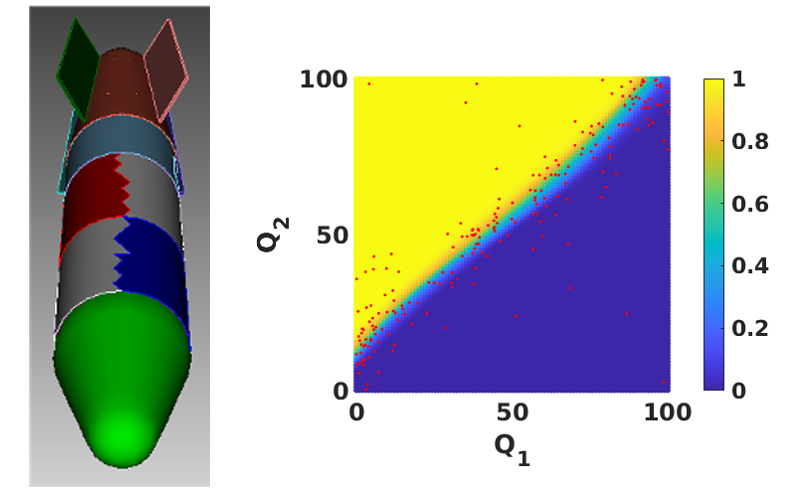
By using the geometry-based classification of the SVMs, researchers can provide the user with probability of failure estimates over the deterministic parameter space while minimizing the number of forward solves needed. In a brute-force approach known as the “lawnmower search,” the determination of the decision boundary in an N-dimensional parameter space would require on the order of pN forward evaluations, where p increases with the parameter resolution. This number is drastically reduced as the adaptive algorithm intelligently selects points to train on, based on the current estimate of the decision boundary in parameter space. Figure 2 illustrates an early result from this project where the team reduced the number of forward evaluations required by a factor of 10.4 during the search for the decision boundary, while preserving the accuracy of the brute-force approach. While this example only has two deterministic variables, this effect is expected to further amplify as dimensionality is increased. This allows an engineer to assess the reliability of a design and integrate this information into the design needs of a specific program by using high-fidelity simulations while simultaneously assessing parametric uncertainty in a timely manner.