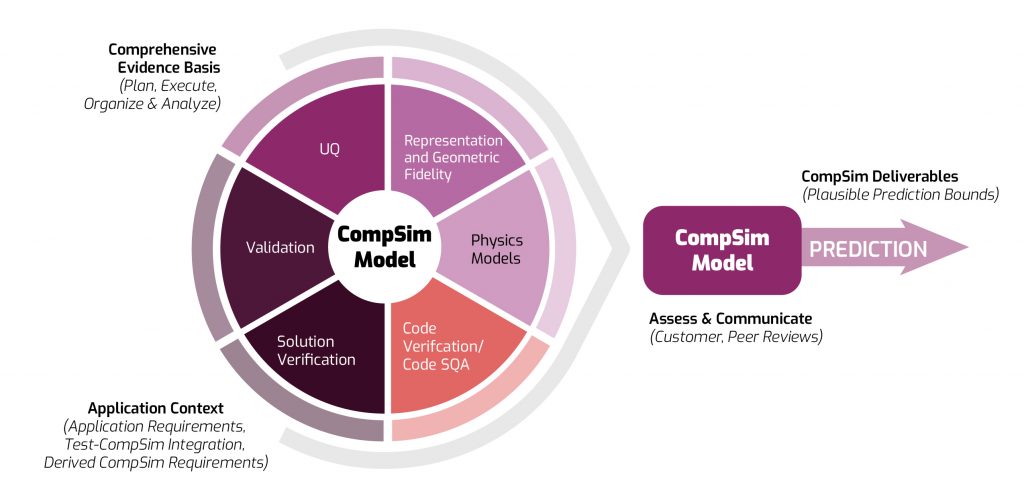
Computational simulation, or CompSim, models are digital prototypes of something a researcher is interested in building or testing. These prototypes make it easier and faster for the researcher to design a product that accomplishes a specific goal without first having to build and test a long list of physical prototypes.
Machine learned models are used in lieu of, complementary to or as surrogates for CompSim models. Machine learned models are useful for situations like pandemic tracking, climate modeling and wherever research and traditional CompSim models are unrealistic or inadequate.
However, a key aspect of using either type of model is knowing whether their simulations are credible. The existing CompSim credibility process provides a proven method for gathering evidence to support the credibility of CompSim predictions (see Figure 1).
Machine learning models are fundamentally different from CompSim models in their relationship to the data. In CompSim, the models are derived from physics or other domain knowledge, and then data is used to calibrate some model parameters or to perform model validation. In machine learning models, there is a primary dependence on the data itself, so developing a machine learning credibility framework requires an initial proof of credibility for the data used to train, test and validate the machine.
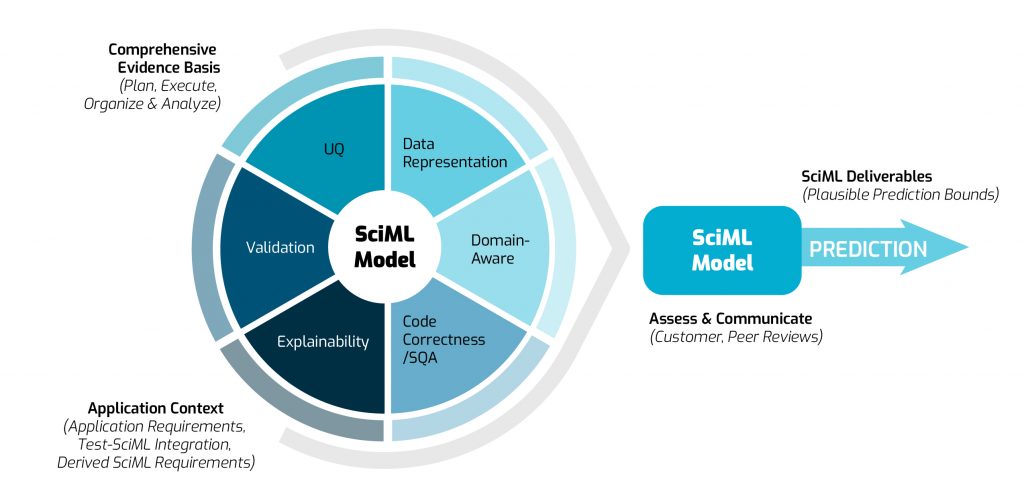
The team has extended the standard CompSim credibility process (Figure 1) and adapted it specifically for SciML (see Figure 2).
- Data representation: Does the data provide a representative population for training/testing/validation?
- Domain-aware: What physical phenomena need to be preserved in the model? Is it captured?
- Code correctness: Can the software quality be assured?
- Solution explainability: Are the model solutions explainable to model customers?
- Validation: Do the model predictions agree with the ground truth data that was not used during training?
- Uncertainty quantification: What sources of uncertainty cannot be mitigated or eliminated? What sources can be mitigated or eliminated?
This SciML framework has been systematically tested and refined through a broad set of prototype SciML examples derived from analysis of test and experimental data. HPC computers were used to discover and calibrate SciML models from large-scale datasets and examine the data provenance, machine learning algorithm influence and impact of expert domain knowledge. All this work is helping refine the SciML modeling and credibility framework to provide increased knowledge and enable trustworthy decision making.