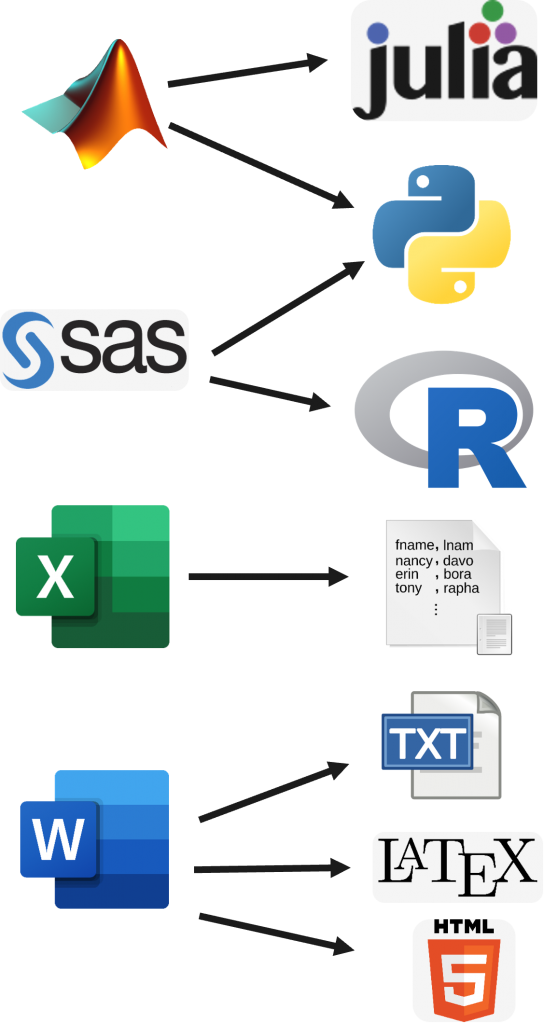
Researchers have many file format choices from txt to py to xlsx and more. FAIR data, however, prioritizes accessible and preservable file formats. Consider the following questions.
Open or proprietary?
Proprietary formats create a paywall for data access. There are many alternative free options to promote FAIRness.
Conversion chart for proprietary to open file formats
Visual representation of the file format conversions
Common or low use?
Some file types such as ras and ctf are only useful to users with machine designed to take them as inputs. These can be converted to a human-interpretable format such as csv.
Supported by many software platforms or one?
When a file is supported by a single software platform, the data becomes dependent on that software platform for data engagement. Support from multiple software platforms creates redundancies for that engagement, which means that if one platform is unavailable the data is still useful and usable. This is critical to data reusability and preservation. A common example of this is .npy files, which are primarily only supported by NumPy. While this format can be useful for day to day use, it is not ideal for data release. For experimental data, machines sometimes output file formats that are primarily only designed for the machine’s specific software (for example, Igor Pro Binary Wave files). This creates a barrier to entry for users who don’t have access to or familiarity with the requisite machine or machine software.
Freestanding or reliant on embedded files/programs/scripts?
Some files can include additional embedded data files, programs, or scripts. The most obvious example of this is Excel documents and PDF’s with embedded files. Embedded file information can be problematic for a variety of reasons–not the least of which is that embedded information constitutes a security risk. Government research institutions (such as Sandia National Labs) cannot engage with embedded external file content which essentially removes a massive base of researchers who might otherwise access your data.
If you have data with embedded file information, the key strategy is to separate that embedded information into its own files. If an excel sheet contains equations, for example, those can be instead computed and stored in their own script and released as a software component of the data. If an excel sheet has embedded information via colors (which are not machine-interoperable when such files are accessed via code), then the information conveyed by those colors should be integrated into a csv-file.
Lossless or lossy?
In information technology, lossy compression or irreversible compression is the class of data compression methods that uses inexact approximations and partial data discarding to represent the content. These techniques are used to reduce data size for storing, handling, and transmitting content.
From Wikipedia, the free encyclopedia
Files with lossy compression permanently lose data each time they are compressed. Files will lossless compression do not.
Compression Type
File Types
Lossless
PNG, PDF, GIF
Lossy
JPEG
Example lossy and lossless file types
Consistency
Human brains are really good at reconciling small differences, but computers are not. Data must be consistent in order to be interoperable. To this end, please consider the following three items.
Some of these files are csv while others are xlsx. These should be standardized to a single file type. Using the accessible and preservable file formats advice, the xlsx files should be converted to csv. Rather than doing this manually, the conversion can be done using python and pandas.
import os
import pandas
filelist = [f'{folder}/{i}' for i in os.listdir(folder) if 'AreaHistogram.xlsx' in i]
for fpath in filelist:
df = pandas.read_excel(fpath)
df.to_csv(fpath.replace('.xlsx', '.csv')
os.remove(fpath)
The names all seem similar but not exactly aligned. Let’s look for common elements.
All start with the material, Mo (molybdenum)
All include a pressure value (e.g., 2mTorr)
All include a power value (e.g., 500W)
All include an index number (e.g., index63)
All include a variant of “area histogram”
Some, but not all, include the date
To standardize these, they should all follow the format: Mo_<pressure>mTorr_<power>W_index<index #>_area_histogram.csv
The conversion can be done via python.
import os
filelist = [i for i in os.listdir(folder) if ('area_histogram.csv' in i) or ('AreaHistogram.csv' in i)]
for filename in filelist:
fileprops = filename.split('_')
pr = [i for i in fileprops if 'mTorr' in i][0]
po = [i for i in fileprops if 'W' in i][0]
index_num = [i.lower() for i in fileprops if 'index' in i.lower()][0]
newfilename = f'Mo_{pr}_{po}_{index_num}_area_histogram.csv'
os.rename(f'{folder}/filename', f'{folder}{newfilename}')
All the files now have a consistent naming scheme!
It is important for the internal format features of a dataset to maintain consistency as well. Check on items that the data creators assume to be true but may not have verified.
Would you use data that is horribly organized? Of course not! Assume that your data users will not look at your documentation until they are forced to and follow these better practices.
Write Directions: Provide ample explanation and direction for your dataset.
Folder Structures: Organize files into folders and subfolders in such a way to make data easy to find.
Classification: Sort by importance, sensitivity, and more.
External Reviewers: When in doubt, ask for a review from someone else – preferably not involved in your project.