
CCR Applied Mathematician Wins DOE Early Career Research Award

CCR researcher Pete Bosler won a Department of Energy Office of Science Early Career Research Award of up to $500,000 annually for five years. The Early Career Research Program, now in its 13th year, is designed to provide support to researchers during their early career years. This year, DOE awarded 83 scientists nationwide, including 27 from the national laboratories and a total of four from Sandia. Bosler’s proposal entitled “High Performance Adaptive Multiscale Simulation with Data-driven Scale Selective Subgrid Parameterizations” aims to explore multiscale simulations that, integrated, could combine individual raindrops, thunderstorms, and the entire global atmosphere, guided by data currently thought too fine to be used, that is, too small to be seen on a data grid, or in other words, subgrid.
See the Sandia news release for more details.
Mike Heroux Receives Outstanding Service Award
CCR researcher Mike Heroux was recently awarded the 2023 Outstanding Service and Contribution Award from the IEEE Computer Society Technical Committee on Parallel Processing. Heroux was recognized “For outstanding service to the high-performance computing community, and significant contributions to the performance and sustainability of scientific software.” The award is given annually to individuals who have had substantial impact on the field through major professional roles, volunteer activities, or other demonstrations of community leadership. The award was presented during a ceremony at the IEEE International Parallel and Distributed Processing Symposium in St. Petersburg, Florida. Mike is the founder and leader of the Trilinos solver project, has held numerous conference and committee leadership roles, and is currently the Director of Software Technology for the US DOE Exascale Computing Project.

June 9, 2023
CCR Researcher Receives EO Lawrence Award

Quantum information scientist Andrew Landahl received a 2021 Ernest Orlando Lawrence Awards, the U.S. Department of Energy’s highest scientific mid-career honor. Landahl was recognized for his “groundbreaking contributions to quantum computing, including the invention of transformational quantum error correction protocols and decoding algorithms, for scientific leadership in the development of quantum computing technology and quantum programming languages and for professional service to the quantum information science community.” He is the first person to receive the EO Lawrence Award in field of quantum information science.
See the Sandia news release for more information on both Sandia winners.
SNL adds Discontinuous Galerkin visualization capability to EMPIRE and ParaView
Sandia National Laboratories in collaboration with Kitware, Inc. added new capabilities to store and visualize Discontinuous Galerkin (DG) simulation results using the Exodus/ParaView workflow to support the EMPIRE plasma physics application. The DG methods employed by EMPIRE were selected because of their natural conservation properties, support of shock capturing methods, and strong spatial locality which are advantageous to solvers relevant to plasmas. However, Sandia’s traditional visualization workflow involving Exodus and ParaView did not support DG without substantial preprocessing. This effort introduced new data structures and visualization support to the software stack to support DG methods including high-order DG methods.
The Sandia team added key pieces of “DG metadata” in combination with the existing Exodus data structures to create a mesh that represents the discontinuities inherent in DG. Kitware then modified ParaView to recognize the DG metadata and use it to “explode” the mesh from a continuous Exodus mesh to a discontinuous internal representation. As part of this process, shared vertices are replicated to give elements independent vertex instances and additional vertices are added as necessary to match the basis order of the mesh to the DG fields. The result is a faithful visualization of the discontinuities that can be used for analysis and debugging. Figure 1 shows the electron density of the 2D Triple Point Problem warped in the Z dimension to illustrate the discontinuity between elements. Areas of the mesh with small discontinuities have a smooth appearance while areas with larger discontinuities have distorted elements and gaps between elements.
This effort has added DG capabilities to the visualization tools that analysts know, understand and trust. With this new capability available, other applications (eg. SPARC and Flexo) have the opportunity to visualize their DG results without requiring additional postprocessing of simulation results.

Secure multiparty computation supports machine learning in sensor networks.
The Cicada project is a collaboration between Sandia National Laboratories and the University of New Mexico to develop the necessary foundations for privacy-preserving machine learning in large networks of autonomous drones. Their approach utilizes secure multiparty communication methods to protect information within decentralized networks of low-power sensors that communicate via radio frequency. These networks are resilient to the random failure of a small fraction of nodes, remain secure even if an adversary captures a small subset of nodes, and are capable of basic machine learning. This new capability will help address national security priorities such as physical security and command, control, and communications.
A video is available with more information on privacy-preserving machine learning at the Autonomy NM Robotics Lab: https://www.youtube.com/watch?v=GM_JuKrw4Ik
For more information on the Cicada software package, visit https://cicada-mpc.readthedocs.io
Machine Learning Enables Large-Scale Quantum Electron Density Calculations
Researchers at Sandia National Laboratories have developed a method for making previously impossible quantum chemistry calculations possible by using machine learning. A long standing problem in the quest to accurately simulate large molecular systems, like proteins or DNA, is the inability to perform accurate quantum chemistry calculations on these large systems. Sandia Truman Fellow Josh Rackers and his collaborators at UCLA, MIT, and École Polytechnique Fédérale de Lausanne were able to train a machine learning model to accurately predict the electron densities of large systems by providing the model with small-scale training examples. This was made possible by utilizing a new type of neural network algorithm, Euclidean Neural Networks, that are especially designed for 3D machine learning problems. The model is able to make quantum chemistry predictions for systems of thousands of atoms in under a second – a calculation that would take decades or more with current quantum chemistry programs.
An arXiv pre-print of this work is available at https://arxiv.org/abs/2201.03726
CCR scientists use gate set tomography to probe inner workings of quantum computers
![Image of The January 20th, 2022 Nature cover shows an artist's impression of the three-qubit silicon device that was created by UNSW physicists, then measured and validated by Sandia quantum information scientists [Image credit: Tony Melov, UNSW].](https://www.sandia.gov/app/uploads/sites/210/2022/06/chip-1.png)
Two papers published in the journal Nature — one coauthored by Sandia researchers — used a Sandia technique called gate set tomography (GST) to demonstrate logic operations exceeding the “fault tolerance threshold” of 99% fidelity in silicon quantum computing processors. Spawned by a Sandia Early Career LDRD in 2012, GST has since been developed at Sandia’s ASCR-funded Quantum Performance Lab. Sandia scientists collaborated with Australian researchers at the University of New South Wales in Sydney to publish one of the Nature papers, showcasing a three-qubit system comprising two atomic nuclei and one electron in a silicon chip. In parallel, a group from Delft University of Technology in the Netherlands used Sandia’s pyGSTi software to demonstrate equally high-fidelity logic using electrons trapped in quantum dots.
For additional information, please see:
Madzik M.T., et al., Precision tomography of a three-qubit donor quantum processor in silicon. Nature 601, 348-353 (2022).
Nature News & Views (Jan. 20, 2022), “Silicon qubits move a step closer to achieving error correction”.
YouTube video on Quantum operations with 99% fidelity – the key to practical quantum computers.
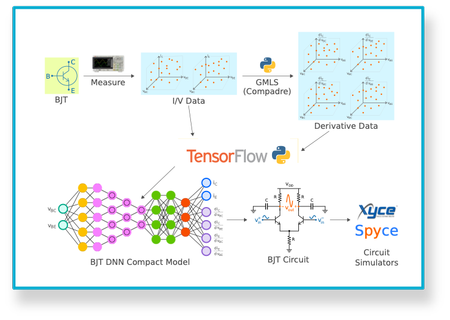
Machine Learning for Xyce Circuit Simulation
The Advanced Simulation and Computing (ASC) initiative to maximize near and long-term Artificial Intelligence (AI) and Machine Learning (ML) technologies on Sandia’s Nuclear Deterrence (ND) program funded a project focused on producing physics-aware machine learned compact device models suited for use in production circuit simulators such as Xyce. While the original goal was only to make a demonstration of these capabilities, the team worked closely with Xyce developers to ensure the resulting product would be suitable for the already large group of Xyce users both internal and external to Sandia. This was done by extending the existing C++ general external interface in Xyce and adding Pybind11 hooks. The result is that with release 7.3 of Xyce, the ability to define machine learned compact device models entirely in Python (the most commonly used machine learning language) and use them with Xyce will be publicly available.
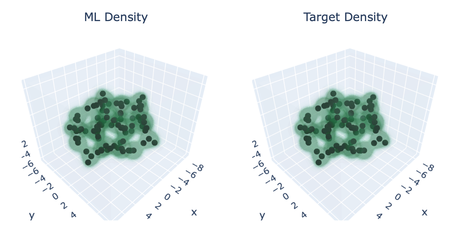
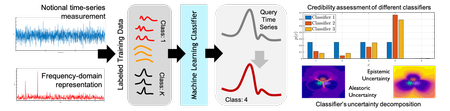
Credibility in Scientific Machine Learning: Data Verification and Model Qualification
The Advanced Simulation and Computing (ASC) initiative on Advanced Machine Learning (AML) aims to maximize near and long-term impact of Artificial Intelligence (AI) and Machine Learning (ML) technologies on Sandia’s Nuclear Deterrence (ND) program. In this ASC-AML funded project, the team is developing new approaches for assessing the quality of machine learning predictions based on expensive/limited experimental data, with focus on problems in the nuclear deterrence (ND) mission domain. Guided by the classical Predictive Capability Maturity Model (PCMM) workflow for Verification, Validation, and Uncertainty Quantification (V&V/UQ), the project aims to rigorously assess the statistical properties of the input features when training a Scientific Machine Learning (SciML) model and examine the associated sources of noise, e.g., measurement noise. This will, in turn, enable the decomposition of output uncertainty into unavoidable aleatory part versus reducible model-form uncertainty. To improve Sandia’s stockpile surveillance analysis capabilities, the team uses signature waveforms collected using non-destructive functioning and identify the most-discriminative input features, in order to assess the quality of a training dataset. By further decomposing uncertainty into its aleatoric and epistemic components, the team will guide computational/sampling resources towards reducing the treatable parts of uncertainty. This workflow will enhance the overall credibility of the resulting predictions and open new doors for SciML models to be credibly deployed to costly or high stakes ND problems.
Automated Ensemble Analysis in Support of Nuclear Deterrence Programs
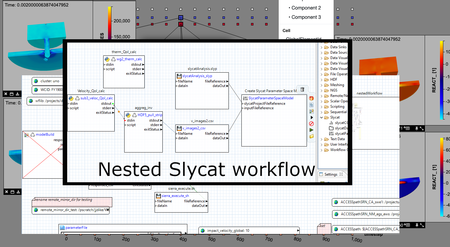
Managing the modeling-simulation-analysis workflows that provide the basis for Sandia’s Nuclear Deterrence programs is a requirement for assuring verifiable, documented, and reproducible results. The Sandia Analysis Workbench (SAW) has now been extended to provide workflow management through the final tasks of ensemble analysis using Sandia’s Slycat framework. This new capability enhances multi-platform modeling-simulation workflows through the Next Generation Workflow (NGW) system. With the goal of providing end-to-end workflow capability to the nuclear deterrence programs, the new technology integrates Slycat and SAW. It fills the workflow gap between computational simulation results and post-processing tasks of ensemble analysis and the characterization of uncertainty quantification (UQ). This work compliments simulation data management while providing encapsulated, targeted sub-workflows for ensemble analysis, verification and validation, and UQ. The integration of Slycat management into SAW affords a common point of control and configuration. This connects analysis with modeling and simulation, and provides a documented provenance of that analysis. The heart of the work is a set of innovative NGW components that harvest ensemble features, quantities of interest (QoIs), simulation responses, and in situ generated images, videos, and surface meshes. These components are triggered on-demand by the workflow engine when the prerequisite data and conditions are satisfied. Executing from an HPC platform, the components apply those artifacts to generate parameterized, user-ready analyses on the Slycat server. These components can eliminate the need for analyst intervention to hand-process artifacts or QoIs. The technology automates data flow and evidence production needed for decision-support in quantification of margins and uncertainty. Finally, these components deliver an automated and repeatable shortcut to Slycat’s meta-analysis crucial for optimizing ensembles, evaluating parameter studies, and understanding sensitivity analysis.
QSCOUT / Jaqal at the Frontier of Quantum Computing
DOE/ASCR is investing over 5 years in Sandia to build and host the Quantum Scientific Computing Open User Testbed (QSCOUT): a quantum testbed based on trapped ions that is available to the research community (led by Susan Clark, 5225). As an open platform, it will not only provide full specifications and control for the realization of all high level quantum and classical processes, it will also enable researchers to investigate, alter, and optimize the internals of the testbed and test more advanced implementations of quantum operations. To maximize the usability and impact of QSCOUT, Sandia researchers in 1400 (Andrew Landahl, 1425) have led the development of the Jaqal quantum assembly language, which has been publicly released in conjunction with a QSCOUT emulator. QSCOUT is currently hosting external user teams from UNM, ORNL, IBM, the University of Indiana, and the University of California at Berkeley for scientific discovery in quantum computing.
For more information visit https://www.sandia.gov/quantum/Projects/QSCOUT.html

May 2021
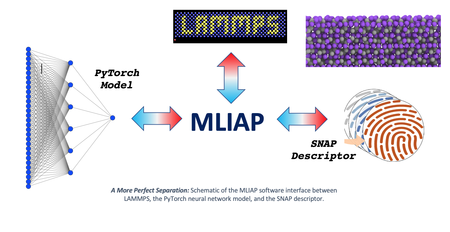
Machine-Learned Interatomic Potentials Are Now Plug-And-Play in LAMMPS
Researchers at Sandia and Los Alamos National Laboratories have discovered a new way to implement machine learning (ML) interatomic potentials in the LAMMPS molecular dynamics code. This makes it much easier to prototype and deploy ML models in LAMMPS and provides access to a vast reservoir of existing ML libraries. The key is to define an interface (MLIAP) that separates the calculation of atomic fingerprints from the prediction of energy. The interface also separates the atomic descriptors and energy models from the specialized LAMMPS data structures needed for efficient simulations on massively parallel computers. Most recently, a new model class has been added to MLIAP that provides access to any Python-based library, including the PyTorch neural network framework. This advancement was made under the DOE SciDAC/FES FusMatML project for the application of machine learning to atomistic models for plasma-facing materials in fusion reactors.
More information on the LAMMPS package for machine-learned interatomic potentials can be found here: LAMMPS MLIAP Package
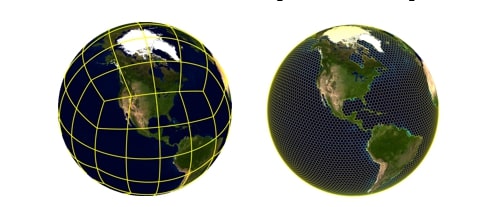
Investigating Arctic Climate Variability with Global Sensitivity Analysis of Low-resolution E3SM.
As a first step in quantifying uncertainties in simulated Arctic climate response, Sandia researchers have performed a global sensitivity analysis (GSA) using a fully coupled ultralow-resolution configuration of the Energy Exascale Earth System Model (E3SM). Coupled Earth system models are computationally expensive to run, making it difficult to generate the large ensembles required for uncertainty quantification. In this research an ultralow version of E3SM was utilized to tractably investigate parametric uncertainty in the fully coupled model. More than one hundred perturbed simulation ensembles of one hundred years each were generated for the analysis and impacts on twelve Arctic quantities of interest were measured using the PyApprox library. The parameter variations show significant impact on the Arctic climate state with the largest impact coming from atmospheric parameters related to cloud parameterizations. To our knowledge, this is the first global sensitivity analysis involving the fully-coupled E3SM. The results will be used to inform model tuning work as well as targeted studies at higher resolution.
For more information on E3SM: https://e3sm.org/
IDAES PSE Computational Platform Wins 2020 R&D 100 Award
The IDAES Integrated Platform is a comprehensive set of open-source Process Systems Engineering (PSE) tools supporting the design, modeling, and optimization of advanced process and energy systems. By providing rigorous equation-oriented modeling capabilities, IDAES helps energy and process companies, technology developers, academic researchers, and the DOE to design, develop, scale-up, and analyze new PSE technologies and processes to accelerate advances and apply them to address the nation’s energy needs. The platform is based on and extends the Pyomo optimization modeling environment originally developed at Sandia. IDAES has taken the core optimization capabilities in Pyomo and not only built a domain-specific process modeling environment, but also expanded the core environment into new areas, including logic-based modeling, custom decomposition procedures and optimization algorithms, model predictive control, and machine learning methods.
The IDAES PSE Computational Platform is developed by the Institute for the Design of Advanced Energy Systems (IDAES) and was recently awarded a 2020 R&D 100 Award. Led by National Energy Technology Laboratory (NETL), IDAES is a collaboration with Sandia National Laboratories, Berkeley Lab, West Virginia University, Carnegie Mellon University, and the University of Notre Dame.
For more information on IDAES, see https://idaes.org

2020 Rising Stars Workshop Supports Women in Computational & Data Sciences
Rising Stars in Computational & Data Sciences is an intensive academic and research career workshop series for women graduate students and postdocs. Co-organized by Sandia and UT-Austin’s Oden Institute for Computational Engineering & Sciences, Rising Stars brings together top women PhD students and postdocs for technical talks, panels, and networking events. The workshop series began in 2019 with a two-day event in Austin, TX. Due to travel limitations associated with the pandemic, the 2020 Rising Stars event went virtual with a compressed half-day format. Nonetheless, it was an overwhelming success with 28 attendees selected from a highly competitive pool of over 100 applicants. The workshop featured an inspiring keynote talk by Dr. Rachel Kuske, Chair of Mathematics at Georgia Institute of Technology, as well as lightning-round talks and breakout sessions. Several Sandia managers and staff also participated. The Rising Stars organizing committee includes Sandians Tammy Kolda (Distinguished Member of Technical Staff, Extreme-scale Data Science & Analytics Dept.) and James Stewart (Sr. Manager, Computational Sciences & Math Group), as well as UT Austin faculty Karen Willcox (Director, Oden Institute) and Rachel Ward (Assoc. Professor of Mathematics).
For more information on Rising Stars, see https://risingstars.oden.utexas.edu

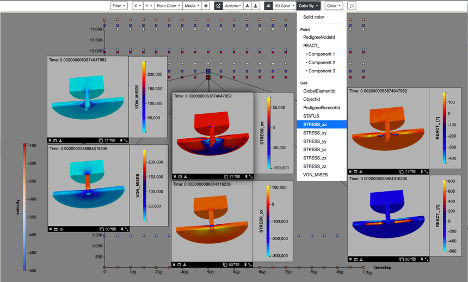
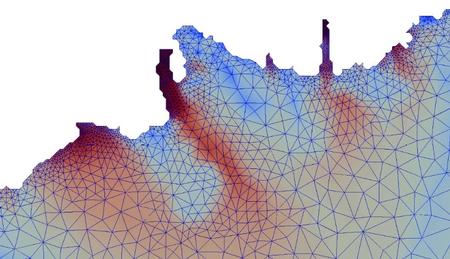
Slycat Enables Synchronized 3D Comparison of Surface Mesh Ensembles
In support of analyst requests for Mobile Guardian Transport studies, researchers at Sandia National Laboratories have expanded data types for the Slycat ensemble-analysis and visualization tool to include 3D surface meshes. Analysts can now compare sets of surface meshes using synchronized 3D viewers, in which changing the viewpoint in one viewer changes viewpoints in all the others. To illustrate this capability, the Slycat team performed an ensemble analysis for a material-modeling study that examines fracturing behavior in a plate after being impacted by a punch. Input parameters include plate and punch density, friction coefficient, Young’s modulus, and initial punch velocity. To compare different mesh variables over the same geometry, the analyst clones a mesh into multiple views, as shown in Figure 1. The two runs represent opposite extremes for the initial punch velocity, with the 3D viewers in the top row showing the fastest initial velocity, and the viewers in the bottom row showing the slowest. The mesh variables in the two rows are vertically matched top and bottom, so by comparing rows, you can compare the distinctly different stress behaviors of the extremes.
This new capability represents a significant advance in our ability to perform detailed comparative analysis of simulation results. Analyzing mesh data rather than images provides greater flexibility for post-processing exploratory analysis.
Sandia and Kitware Partner to Improve Performance of Volume Rendering for HPC Applications
In collaboration with researchers at Sandia, Kitware developers have made significant performance improvements to volume rendering for large-scale applications. First, Kitware significantly improved unstructured-grid volume rendering. In a volume-rendering example for turbulent flow with 100 million cells on 320 ranks on a Sandia cluster, the volume rendered in 8 seconds using the new method, 122 seconds for the old method, making unstructured-grid visualization a viable in-situ option for applications. Second, Kitware created a new “resample-to-image” filter that uses adaptive-mesh refinement to calculate and resample the image to the smaller mesh with minimal visualization artifacts. The new filter reduces the amount of data required for visualization and provides a potential performance improvement (more testing is needed). These improvements were driven by Sandia researchers for the NNSA Advanced Simulation and Computing program in support of the P&EM, V&V, and ATDM ASC sub-elements as part of a Large-Scale Calculation Initiative (LSCI) project. Kitware funding was provided through a contract with the ASC/CSSE sub-element.

November 1, 2020
CCR Researcher Discusses IO500 on Next Platform TV
CCR system software researcher Jay Lofstead appeared on the September 3rd episode of “Next Platform TV” to discuss the IO500 benchmark, including how it is used for evaluating large- scale storage systems in high-performance computing (HPC) and the future of the benchmark. Jay’s discussion with Nicole Hemsoth of the Next Platform starts at the 32:04 mark of the video. In the interview, Jay describes the origins of the IO500 benchmark and the desire to provide a standard method for understanding how well an HPC storage system is performing for different workloads and different storage and file system configurations. Jay also describes how the benchmark has evolved since its inception, as well as the influence of the benchmark, and the ancillary impacts of ranking IO systems. More details and the entire episode are here:
https://www.nextplatform.com/2020/09/03/next-platform-tv-for-september-3-2020/

Sandia-led Earth System Modeling Project Featured in ECP Podcast
CCR researcher Mark Taylor was interviewed in a recent episode of the “Let’s Talk Exascale” podcast from the Department of Energy’s Exascale Computing Project (ECP). Taylor leads the Energy Exascale Earth System Model – Multiscale Modeling Framework (E3SM-MMF) subproject, which is working to improve the ability to simulate the water cycle and processes around precipitation. The podcast and a transcript of the interview can be found here.
Sandia Researchers Collaborate with Red Hat on Container Technology
Sandia researchers in the Center for Computing Research collaborated with engineers from Red Hat, the world’s leading provider of open source solutions for enterprise computing, to enable more robust production container capabilities for high-performance computing (HPC) systems. CCR researchers demonstrated the use of Podman, which allows ordinary users to build and run containers without needing the elevated security privileges of an administrator, on the Stria machine at Sandia. Stria is an unclassified version of Astra, which was the first petascale HPC system based on an Arm processor. While Arm processors have shown to be very capable for HPC workloads, they are not as prevalent in laptops and workstations as other processors. To address this limitation, Podman provides the ability to build containers directly on machines like Stria and Astra without requiring root-level access. This capability is a critical advancement in container functionality for the HPC application development environment. The CCR team is continuing to work with Red Hat on improving Podman for traditional HPC applications as well as machine learning and deep learning workloads. More details on this collaboration can be found here:
Key Numerical Computing Algorithm Implemented on Neuromorphic Hardware
Researchers in Sandia’s Center for Computing Research (CCR) have demonstrated using Intel’s Loihi and IBM’s TrueNorth that neuromorphic hardware can efficiently implement Monte Carlo solutions for partial differential equations. CCR researchers had previously hypothesized that neuromorphic chips were capable of implementing critical Monte Carlo algorithm kernels efficiently at large scales, and this study was the first to demonstrate that this approach could be used to approximate solutions to arrive at a steady-state PDE solution. This study formalized the mathematical description of PDEs into an algorithmic form suitable for spiking neural hardware and highlighted results from implementing this spiking Monte Carlo algorithm on Sandia’s 8-chip Loihi test board and the IBM TrueNorth chip at Lawrence Livermore National Laboratory. These results confirmed that the computational costs scale highly efficiently with model size; suggesting that spiking architectures such as Loihi and TrueNorth may be highly desirable for particle-based PDE solutions. This work was funded by Sandia’s Laboratory Directed Research and Development (LDRD) program and the DOE Advanced Simulation and Computing (ASC) program. The paper has been accepted to the 2020 International Conference on Neuromorphic Systems (ICONS) and is available at https://arxiv.org/abs/2005.10904
CCR Researcher Discusses Ceph Storage on Next Platform TV
CCR system software researcher Matthew Curry appeared on the June 22nd episode of “Next Platform TV” to discuss the increased use of the Ceph storage system in high-performance computing (HPC). Matthew’s interview with Nicole Hemsoth of the Next Platform starts at the 18:40 mark of the video. In the interview, Matthew describes the Stria system, which is an unclassified version of Astra, which was the first petascale HPC system based on the Arm processor. Matthew also describes the use of the Ceph storage system and some of the important aspects that are being tested and evaluated on Stria. More details and the entire episode are here.

Sandia to receive Fujitsu supercomputer processor
This spring, CCR researchers anticipate Sandia becoming one of the first DOE laboratories to receive the newest A64FX Fujitsu processor, a Japanese Arm-based processor optimized for high-performance computing.The 48-core A64FX processor was designed for Japan’s soon-to-be-deployed Fugaku supercomputer, which incorporates high-bandwidth memory. It also is the first to fully utilize wide vector lanes that were designed around Arm’s Scalable Vector Extensions. These wide vector lanes make possible a type of data-level parallelism where a single instruction operates on multiple data elements arranged in parallel. Penguin Computer Inc. will deliver the new system — the first Fujitsu PRIMEHPC FX700 with A64FX processors. Sandia will evaluate Fujitsu’s new processor and compiler using DOE mini- and proxy-applications and will share the results with Fujitsu and Penguin. More details are available here.

Sandia Covid-19 Medical Resource Modeling
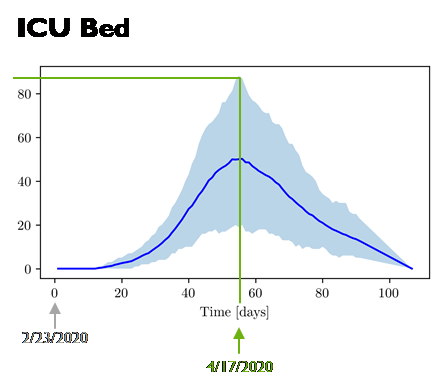
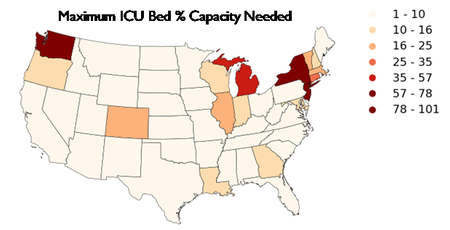
As part of the Department of Energy response to the novel coronavirus pandemic of 2020, Sandia personnel developed a model to predict medical resources needed, including medical practitioners (e.g. ICU nurses, physicians, respiratory therapists), fixed resources (regular or ICU beds and ventilators), and consumable resources (masks, gowns, gloves, etc.)
Researchers in Center 1400 developed a framework for performing uncertainty analysis on the resource model. The uncertainty analysis involved sampling 26 input parameters using the Dakota software. The sampling was performed conditional on the patient arrival streams, which were derived from epidemiology models and had a significant effect on the projected resource needs.
Using two of Sandia’s High Performing Computing clusters, the generated patient streams were run through the resource model for each of 3,145 counties in the United States, where each county-level run involved 100 samples per scenario. Three different social distancing scenarios were investigated. This resulted in approximately 900,000 individual runs of the medical resource model, requiring over 500 processor hours on the HPCs. The results included mean estimates per resource per county, as well as uncertainty in those estimates (e.g., variance, 5th and 95th quantile, and exceedance probabilities). Example results are shown in Figures 1-2. As updated patient stream projections become available from the latest epidemiology models, the analysis can be re-run quickly to provide resource projections in rapidly changing environments.
For more information on Sandia research related to COVID-19, please visit the COVID-19 Research website.
Sandia-led Supercontainers Project Featured in ECP Podcast
As the US Department of Energy’s (DOE) Exascale Computing Project (ECP) has evolved since its inception in 2016, what’s known as containers technology and how it fits into the wider scheme of exascale computing and high-performance computing (HPC) has been an area of ongoing interest in its own right within the HPC community.
Container technology has revolutionized software development and deployment for many industries and enterprises because it provides greater software flexibility, reliability, ease of deployment, and portability for users. But several challenges must be addressed to get containers ready for exascale computing.
The Supercontainers project, one of ECP’s newest efforts, aims to deliver containers and virtualization technologies for productivity, portability, and performance on the first exascale computing machines, which are planned for 2021.
ECP’s Let’s Talk Exascale podcast features as a guest Supercontainers project team member Andrew Younge of Sandia National Laboratories. The interview was recorded this past November in Denver at SC19: The International Conference for High Performance Computing, Networking, Storage, and Analysis.
Steve Plimpton Awarded the 2020 SIAM Activity Group on Supercomputing Career Prize
Steve Plimpton has been awarded the 2020 Society for Industrial and Applied Mathematics (SIAM) 2020 Activity Group on Supercomputing Career Prize. This prestigious award is given every two years to an outstanding researcher who has made broad and distinguished contributions to the field of algorithm development for parallel scientific computing. According to SIAM, the Career Prize recognizes Steve’s “seminal algorithmic and software contributions to parallel molecular dynamics, to parallel crash and impact simulations, and for leadership in modular open-source parallel software.”
Steve is the originator of several successful software projects, most notably the open-source LAMMPS code for molecular dynamics. Since its release in 2004, LAMMPS has been downloaded hundreds of thousands of times and has grown to become a leading particle-based materials modeling code worldwide. Steve’s leadership in parallel scientific computing has led to many opportunities for the Center for Computing Research to collaborate on high-performance computing projects both within and outside Sandia National Laboratories.

Karen Devine awarded the Society of Women Engineers 2019 Prism Award
Karen Devine has been awarded the Society of Women Engineers (SWE) 2019 Prism Award. According to SWE, “the Prism Award recognizes a woman who has charted her own path throughout her career, providing leadership in technology fields and professional organizations along the way.” Karen has been deservedly awarded this honor based on her contributions as a “computer science researcher, project leader, customer liaison, mentor and STEM outreach advocate.” Her contributions in delivering algorithms and high-quality software that improve the performance of engineering simulation codes at Sandia are particularly noteworthy.
Karen has been a trailblazer for open-source software practices and policies in Sandia. Now her software is “used in national laboratories, industry, and universities world-wide, with 4500+ downloads of just one of her software libraries.” Karen has demonstrated “strong and effective leadership of small software teams, multi-million dollar projects across many national laboratories, local STEM service projects, and international professional societies.” Karen will be presented with the Prism Award at SWE’s WE19 conference on November 7.

Sandia, PNNL, and Georgia Tech Partner on New AI Co-Design Center
Sandia National Laboratories, Pacific Northwest National Laboratory, and the Georgia Institute of Technology are launching a research center that combines hardware design and software development to improve artificial intelligence technologies. The Department of Energy Office of Advanced Scientific Computing Research (ASCR) will provide $5.5 million over three years for the research effort, called ARtificial Intelligence-focused Architectures and Algorithms (ARIAA). This new collaboration is intended to encourage researchers at the three institutions, each with their own specialty, to simulate and evaluate artificial intelligence hardware when employed on current or future supercomputers. Researchers also should be able to improve AI and machine-learning methods as they replace or augment more traditional computation methods. See this press release for more details.
Astra Supercomputer Team Wins NNSA Defense Programs Award of Excellence
The Astra Supercomputer Team was recently awarded an NNSA Defense Programs Award of Excellence “For excellence in design, acquisition, and integration of the Astra prototype System.” These prestigious annual awards are granted to National Security Enterprise teams and individuals across the NNSA complex to recognize significant contributions to the Stockpile Stewardship Program. The Astra team was one of two Sandia teams to receive an Exceptional Achievement Award at a recent ceremony that recognized a total of 31 teams and three individuals from Sandia. The team successfully delivered the first advanced prototype system for NNSA’s Advanced Simulation and Computing (ASC) Program, moving from requirements definition, through acquisition to delivery, integration, and acceptance of the large-scale computing system in less than twelve months. The Astra system is the world’s largest and fastest supercomputer based on Arm processors. The team is composed of managers, staff, and contractors from the Center for Computing Research, the Center for Computer Systems and Technology Integration, and the Information Technology Services Center.


CCR Researcher Ryan Grant Honored by Queen’s University
CCR Researcher Ryan Grant was recently recognized by his alma mater as one of the top 125 engineering alumni or faculty of Queen’s University during a celebration of the 125thanniversary of the Faculty of Engineering and Applied Science. The award recognizes the achievements of alumni and faculty who are outstanding leaders in their field and represent excellence in engineering. Winners were recognized in March during a ceremony at the university in Kingston, Ontario, Canada. Ryan received his Bachelor of Applied Science, Master of Science in Engineering, and Ph.D. in Computer Engineering from Queen’s, and he is a Principal member of technical staff in the Scalable System Software department with expertise in high-performance interconnect technologies.

CCR Researcher Jay Lofstead Co-Authors Best Paper at HPDC’19
CCR Researcher Jay Lofstead and his co-authors from the Illinois Institute of Technology have been awarded Best Paper at the recent 2019 ACM International Symposium on High- Performance Parallel and Distributed Computing. Their paper entitled “LABIOS: A Distributed Label-Based I/O System” describes an approach to supporting a wide variety of conflicting I/O workloads under a single storage system. The paper introduces a new data representation called a label, which more clearly describes the contents of data and how it should be delivered to and from the underlying storage system. LABIOS is a new class of storage system that uses data labeling and implements a distributed, fully decoupled, and adaptive I/O platform that is intended to grow in the intersection of High-Performance Computing and Big Data. Each year the HPDC Program Chairs select the Best Paper based on reviews and discussion among the members of the Technical Program Committee. The award is named in memory of Karsten Schwan, a professor at Georgia Tech who made significant and lasting contributions to the field of parallel and distributed computing.


Warren Davis Earns National Honors in Leadership and Technology
Warren Davis, received his award during the conference in Washington, D.C., Feb. 7-9, 2019. The annual meeting recognizes black scientists and engineers and is a program of the national Career Communications Group, which advocates for corporate diversity.
This scientist wants to help you see like a computer.
If you saw all the aquariums that fill Davis’ home, you might think he was a pet lover. But you’d be wrong. Davis just has a passion for recreating things.
“I’ve got a sand bed that does denitrification in a certain layer,” mimicking a natural aquatic ecosystem, Davis said. “I’ve got animals that sift the sand bed so it doesn’t become anoxic. I have things that eat uneaten food particles that get trapped under the rocks.” It’s not a perfect model, he said, but it’s close.
Davis is also adept at recreating natural, mechanical processes to solve problems in engineering. In these cases, he takes natural phenomena — like air flowing over a surface or a person taking a step — and uses machine learning to explain them mathematically with an equation, also called a function. Machine learning can approximate complex processes much faster than they can be numerically solved, which saves companies time and resources if, for example, they want to predict how well a proposed aircraft design would hold up in flight. These savings compound when designers want to simulate multiple iterations.
“That’s what I do. I try to learn the functions that we care about,” Davis said.
He also has taken a leadership role helping Sandia and its business partners incorporate machine learning into their own research and development programs. On multiple occasions, he says, this addition has transformed the way they work, making their research more efficient and agile long after his project with them has ended.
The technique sometimes delivers unexpected solutions, too.
“When I’m able to take a data set and come up with something people haven’t seen before or some underlying function it is truly an amazing, almost magical feeling,” he said.
Davis’ work earned him a Research Leadership award.
Sandia news media contact: Troy Rummler, trummle@sandia.gov
Paper was published in the Journal of Policy and Complex Systems. L. W. E. Epifanovskaya, K. Lakkaraju, J. Letchford, M. C. Stites, J. C. Reinhardt, and J. Whetzel. Modeling economic interdependence in deterrence using a serious game. Journal on Policy and Complex Systems, 4(SAND-2018-7419J), 2018.

Kokkos User Group Meeting
The Kokkos team is announcing the first Kokkos User Group Meeting to be held in Albuquerque New Mexico, USA April 23rd through 25th. The meeting will give the growing Kokkos community a chance to present progress in adopting Kokkos, exchange experiences, discuss challenges and help set priorities for the future roadmap of Kokkos. Projects are invited to give a 20 minute presentation. Application talks are encouraged to focus on technical and algorithmic challenges in adopting Kokkos and how Kokkos’s capabilities were used to overcome those.
Power API and LAMMPS Win R&D 100 Awards
Two CCR technologies have won 2018 R&D100 Awards. Each year, R&D Magazine names the 100 most technologically significant products and advancements, recognizing the winners and their organizations. Winners are selected from submissions from universities, corporations, and government labs throughout the world. This year’s winners include the Power API and LAMMPS. The Power API was also recognized with a Special Recognition Award for corporate social responsibility. Sandia garnered a total of five R&D100 Awards. The Power API is portable programming interface for developing applications and tools that can be used to control and monitor the power use of high-performance computing systems in order to improve energy efficiency. LAMMPS is a molecular dynamics modeling and simulation application designed to run on large-scale high performance computing systems. Winners were announced at a recent ceremony at the R&D 100 Conference.

Astra Supercomputer is Fastest Arm-Based Machine on Top 500 List
Sandia’s Astra is the world’s fastest Arm-based supercomputer according to the just released TOP500 list, the supercomputer industry’s standard. With a speed of 1.529 petaflops, Astra placed 203rd on a ranking of top computers announced at SC18, the International Conference for High Performance Computing, Networking, Storage, and Analysis, in Dallas. A petaflop is a unit of computing speed equal to one thousand million million (1015) floating-point operations per second. Astra achieved this speed on the High-Performance Linpack benchmark. Astra is one of the first supercomputers to use processors based on Arm technology. The machine’s success means the supercomputing industry may have found a new potential supplier of supercomputer processors, since Arm designs are available for licensing. More details are in this article.

Power API and LAMMPS Named R&D 100 Award Finalists
Two CCR technologies have been named as finalists for the 2018 R&D100 Awards. Each year, R&D Magazine names the 100 most technologically significant products and advancements, recognizing the winners and their organizations. Winners are selected from submissions from universities, corporations, and government labs throughout the world. This year’s finalists include the Power API and LAMMPS. The Power API is portable programming interface for developing applications and tools that can be used to control and monitor the power use of high-performance computing systems in order to improve energy efficiency. LAMMPS is a molecular dynamics modeling and simulation application designed to run on large-scale high performance computing systems. The final award winners will be announced at a ceremony at the R&D 100 Conference in mid-November.
Sandia Joins the Linaro HPC Special Interest Group
Sandia National Laboratories has joined Linaro’s High Performance Compute (HPC) Special Interest Group as an advanced end user of mission-critical HPC systems. Linaro Ltd, is the open source collaborative engineering organization developing software for the Arm ecosystem. Sandia recently announced Astra, one of the first supercomputers to use processors based on the Arm architecture in a large-scale high-performance computing platform. This system requires a complete vertically integrated software stack for Arm: from the operating system through compilers and math libraries. Sandia and Linaro will work together with the other members of the HPC SIG to jointly address hardware and software challenges, expand the HPC ecosystem by developing and proving new technologies and increase technology and vendor choices for future platforms. More info is available here.
Astra – An Arm-Based Large-Scale Advanced Architecture Prototype Platform
Astra, one of the first supercomputers to use processors based on the Arm architecture in a large-scale high-performance computing platform, is being deployed at Sandia National Laboratories. Astra is the first of a potential series of advanced architecture prototype platforms, which will be deployed as part of the Vanguard program that will evaluate the feasibility of emerging high-performance computing architectures as production platforms. The machine is based on the recently announced Cavium Inc. ThunderX2 64-bit Arm-v8 microprocessor. The platform consists of 2,592 compute nodes, of which each is 28-core, dual-socket, and will be at a theoretical peak of more than 2.3 petaflops, equivalent to 2.3 quadrillion floating-point operations (FLOPS), or calculations, per second. While being the fastest is not one of the goals of Astra or the Vanguard program in general, a single Astra node is roughly one hundred times faster than a modern Arm-based cellphone. More details are available here.

CCR Researcher Kurt Ferreira Co-Authors Best Paper at APDCM Workshop
CCR Researcher Kurt Ferreira and his co-authors have been awarded Best Paper at the upcoming Workshop on Advances in Parallel and Distributed Computational Models (APDCM) at the International Parallel and Distributed Processing Symposium. Their paper entitled “Optimal Cooperative Checkpointing for Shared High-Performance Computing Platforms” proposes a cooperative checkpoint scheduling policy that combines optimal checkpointing periods with I/O scheduling in an effort to ensure minimal overheads in the presence of bursty, competing I/O. This work provides crucial analysis and direct guidance on maximizing throughput on current and future extreme-scale platforms. This year marks the 20th APDCM Workshop, which intends “to provide a timely forum for the exchange and dissemination of new ideas, techniques and research in the field of the parallel and distributed computational models.”
The Next Platform Highlights CCR Work on Memory-Centric Programming
A recent article from The Next Platform, an online publication that offers in-depth coverage of high-end computing, recently featured an article entitled “New Memory Challenges Legacy Approaches to HPC Code.” The article discusses a paper co-authored by CCR researcher Ron Brightwell that was published last November as part of the Workshop on Memory Centric Programming for HPC at the SC’17 conference. In the article, Brightwell and one of his co- authors, Yonghong Yan from the University of South Carolina, discuss the programming challenges created by recent advances in memory technology and the deepening memory hierarchy. The article examines the notion of memory-centric programming and how programming systems need to evolve to provide better abstractions to help insulate application developers from the complexities associated with current and future advances in memory technology for high-performance computing systems.

NVIDIA has invited SNL to present results of a GPU performant shock hydrodynamics code at their Super Computing (SC17) booth.
NVIDIA has invited SNL to present results of a GPU performant coupled hydrodynamics, low Magnetic Reynolds number (low Rm) code at their Super Computing 17 (SC17) booth. Researchers at Sandia are developing a new shock hydrodynamics capability, based on adaptive Lagrangian techniques targeted at next generation architectures. The code simulates shock hydrodynamics on GPU architectures using the Kokkos library to provide portability across architectures. Mesh and field data management, as well as adaptive Lagrangian operations are being developed to run exclusively on the GPU. New algorithms using tetrahedral elements and a predictor-corrector time integrator have been implemented. Low Rm physics is solved using NVIDIA’s AmgX GPU-aware, algebraic multigrid solver. Using an exemplar problem provided by our NW partners we have demonstrated good scaling and performance on next generation architectures. Notably, the exemplar problem demonstrates the advantages of a device-centric design philosophy, where the hydrodynamics physics solve, including adaptivity and remapping, are hosted on the coprocessor with exceptional performance on the GPU relative to traditional multi-core architectures. Additionally, solve times for the low Rm physics with the AmgX software demonstrate sub-second solve times for million degree of freedom problems. Next steps include full-scale testing on Trinity (on both the Haswell and KNL partitions) as well as Sierra as it becomes available, the addition of robust treatment for material/material interactions and the inclusion of more comprehensive MHD physics.
Released VTK-m user’s guide, version 1.1
Researchers at Sandia National Laboratories, in collaboration with Kitware Inc., Oak Ridge National Laboratory, Los Alamos National Laboratory, and the university of Oregon, are proud to release VTK-m version 1.1. The VTK-m library provides highly parallel code to execute visualization on many-core processors like GPUs, multi-core CPUs, and other hardware we are likely to see at for Exascale HPC. This release of VTK-m includes critical core features including filter structures and key reduction. Also provided by this release are several new filters including external faces, gradients, clipping, and point merging. Also provided with this release is a comprehensive VTK-m User’s Guide providing detailed instruction and reference for using and editing VTK-m.

DOE award to develop new quantum algorithms for simulation, optimization, and machine learning
The Department of Energy’s Office of Science recently awarded $4.5M over three years to a multi-institutional and multi-disciplinary team led by Dr. Ojas Parekh (1464) to explore the abilities of quantum computers in three interrelated areas: quantum simulation, optimization, and machine learning, each highly relevant to the DOE mission. The QOALAS (Quantum Optimization and Learning and Simulation) project brings together some the world’s top experts in quantum algorithms, quantum simulation, theoretical physics, applied mathematics, and discrete optimization from Sandia National Laboratories, Los Alamos National Laboratory, California Institute of Technology, and University of Maryland. The QOALAS team will leverage and unearth connections between simulation, optimization, and machine learning to fuel new applications of quantum information processing to science and technology as well as further investigate the potential of quantum computers to solve certain problems dramatically faster or with better fidelity than possible with classical computers.
DARPA/Amazon/IEEE Graph Challenge Champion
A Sandia team from the Center for Computational Research (Michael Wolf, Mehmet Deveci, Jon Berry, Si Hammond, and Siva Rajamanickam) was awarded champion status in the 2017 DARPA/Amazon/IEEE Graph Challenge (http://graphchallenge.mit.edu/champions) for their fast triangle counting implementation KKTri. KKTri was developed as part of the KokkosKernels framework, leveraging linear algebra-based triangle counting algorithms developed in the data analytics miniapp miniTri and performance portable on-node parallelism provided by Kokkos. KKTri was able to count 35 billion triangles (in a 1.2 billion edge graph) in 43 seconds on a single compute node. The work is described in the paper: Wolf, Deveci, Berry, Hammond, Rajamanickam. “Fast Linear Algebra Based Triangle Counting with KokkosKernels,” Proceedings of IEEE HPEC, 2017.
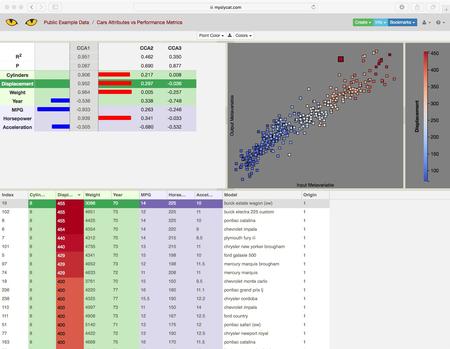
Slycat™ Expands External Access Through Demonstration Servers
The demonstration version of the Slycat™ server, Sandia National Laboratories’ open-source ensemble analysis and visualization system, has been released as a Docker container at https://hub.docker.com/r/slycat/slycat-developer/. This distribution provides a fully-functional webserver, preloaded with example Slycat™ models and test data. This release is intended to facilitate broader access to Slycat™ outside of Sandia, and to allow other Laboratories or academic institutions to experiment with Slycat’s functionality. Additionally, TechMilo, a contractor contributing to Slycat™, has setup a demonstration Slycat™ server outside of Sandia at https://myslycat.com. This site provides the most accessible platform for demonstrating Slycat™ externally (username: demo, password: demo) and is also preloaded with example models for user exploration. (POC: Patricia Crossno, pjcross@sandia.gov)
CCR Researcher Jay Lofstead Helps Unveil First IO-500 Benchmark Results
CCR researcher Jay Lofstead, together with collaborators John Bent from Seagate, Julian Kunkel from the German Climate Computing Center, and Georges Markomanolis of King Abdullah University of Science and Technology released the first results of the IO-500 benchmark during a birds-of-a-feather (BOF) gathering at the recent Supercomputing conference. Similar to the popular Top 500 list that ranks the fastest supercomputers in the world twice a year, the IO-500 list is a composite benchmark that measures the performance and scalability of storage systems intended to serve large-scale parallel computing platforms and applications. Unlike other benchmarks and the resulting rankings, IO-500 uses the composite ranking to motivate both documenting storage systems over time as well as collecting best practices for achieving high performance by encouraging ‘gaming’ easy tests while revealing what is done. More details on the motivation for the benchmark, the results, and the Virtual Institute for I/O (VI4IO) can be found in this article by The Next Platform.
CCR Researcher Delivered Keynote at EuroMPI/USA
CCR researcher Ron Brightwell delivered one of three keynote talks at the recent EuroMPI/USA conference held at Argonne National Laboratory. The Message Passing Interface (MPI) is a de- facto standard programming interface and is the most popular programming system used in high-performance parallel computing, and EuroMPI is an annual conference focused on research activities surrounding MPI and high-performance networking technologies. The conference is typically held in Europe, but this year was held in the US to commemorate the 25th anniversary of the initial meetings that led to the development of the MPI Standard. The keynote talk, entitled “What Will Impact the Future Success of MPI?,” examined current and future challenges that may impact the ability of MPI to continue to dominate the parallel computing landscape for the next 25 years.

AMD Leverages Sandia Technology to Improve GPU Networking
At the recent International Conference on High Performance Computing, Networking, Storage, and Analysis (SC’17), Michael LeBeane from AMD presented a research paper entitled “GPU Triggered Networking for Intra-Kernel Communications.” The paper describes an approach using triggered operations to improve networking performance for systems, such as the Titan machine at Oak Ridge National Laboratory, that employ both traditional processors and graphics processing units (GPUs). Triggered operations are an event-driven technique for initiating data transfers directly from a network interface controller (NIC). Using triggered operations for GPUs is shown to reduce latency performance by 35% compared to other methods. Triggered operations are a key capability of Sandia’s Portals 4 network programming interface, which is intended to enable the design and development of high-performance interconnect hardware. In addition to leveraging Portals 4 triggered operations to improve GPU communication, the simulation environment used in the study is also based on a model of a Portals 4 NIC.

CCR Researchers Co-Author Best Paper Nominee at SC’17
CCR system software researchers Ryan Grant and Ron Brightwell are co-authors on the paper entitled “sPIN: High-Performance Streaming Processing in the Network,” which was one of five papers nominated for Best Paper at the recent 2017 International Conference on High Performance Computing, Networking, Storage and Analysis (SC’17). The paper describes a portable programming environment for offloading packet processing that seeks to improve application performance by reducing the amount of data transferred into host memory and by allowing for more efficient computing on data transferred over the network. A cycle-accurate simulation environment was used to demonstrate the effectiveness of the approach for several different application scenarios. The sPIN approach leverages several capabilities provided by Sandia’s Portals network programming interface. The SC conference series is the premier venue for the high-performance computing community, attracting more than ten thousand attendees each November. This work was supported by NNSA’s Advanced Simulation and Computing program.

CCR Researchers Author Best Paper Nominee at IEEE CloudCom’17
CCR system software researchers Andrew Younge, Kevin Pedretti, Ryan Grant, and Ron Brightwell authored the paper entitled “A Tale of Two Systems: Using Containers to Deploy HPC Applications on Supercomputers and Clouds,” which is one of three papers nominated for Best Paper in Cloud Architecture at the upcoming 2017 IEEE International Conference on Cloud Computing Technology and Science. This paper defines a model for parallel application DevOps and deployment using containers to enhance developer workflows and provide container portability from laptop to clouds or supercomputers. Initial application development, debugging, and testing can be done on cloud resources, such as Amazon EC2, and then seamlessly migrated to a Cray supercomputer using the Singularity container framework. Configured appropriately, the container environment is able to deliver native performance on the Cray system. IEEE CloudCom is the premier conference on cloud computing technologies, attracting participants from the fields of big data, systems architecture, services research, virtualization, security and privacy, high performance computing, with an emphasis on how to build cloud computing platforms with real impact. This work was supported by NNSA’s Advanced Simulation and Computing program.

Three staff in the Non-Conventional Computing Technologies department (1425) recently made high-profile technical communications.
Three staff in the Non-conventional Computing Technologies department (1425) recently made high-profile technical communications: Kenneth Rudinger coauthored a paper published in Physical Review Letters on a robust method for phase estimation for qubits: “Experimental demonstration of cheap and accurate phase estimation.” His co-authors were Shelby Kimmel, Joint Center for Quantum Information and Computer Science (QuICS) at UMD; and Daniel Lobser and Peter Maunz of Sandia’s Photonic Microsystems Technologies department. The paper presents a targeted, but efficient and very useful subset of information on qubit performance that is part of the more comprehensive, but also more laborious analysis developed at Sandia, known as Gate Set Tomography. Michael Frank presented “Foundations of Generalized Reversible Computing” at the 9th Conference on Reversible Computing, held in July in Kolkata, India. Michael’s paper and presentation summarize his development of a new theory of Generalized Reversible Computing (GRC), based on a rigorous quantitative formulation of Landauer’s Principle, that precisely characterizes the minimum requirements for a computation to avoid information loss and energy dissipation. He shows that a much broader range of computations are reversible than has been previously identified. Andrew Landahl presented a well-received overview talk on quantum computing at the recent, invitation-only, Salishan conference on High Speed Computing (http://salishan.ahsc-nm.org/). His talk, Quantum Computing: Cladogenesis Beyond Exascale HPC, was part of a session on quantum computing that aimed to acquaint the audience of leaders in conventional high-performance computing with the elements of quantum information processing.
![FIG. 1: (a) RPE and (b) GST experimental sequences. Each sequence starts with the state p and ends with the two-outcome measurement M. (a) An RPE sequence consists of repeating the gate in question either L orL + 1 times. (b) In GST, a gate sequence Fi is applied to simulate a state preparation potentially different from p. This is followed by [L/|gk|I] applications of a germ—a short gate sequence gk of length |gk|. Finally, a sequence Fj is applied to simulate a measurement potentially different from M.](https://www.sandia.gov/app/uploads/sites/210/2022/06/Aidun_580.jpg)
Inside HPC – MUG Keynote Featuring CCR Researcher Ron Brightwell
The HPC news blog insideHPC recently posted a video of a keynote talk at the MVAPICH User Group Meeting given by CCR researcher Ron Brightwell. The keynote, entitled “Challenges and Opportunities for HPC Interconnects and MPI,” examines challenges created directly by hardware diversity as well as indirectly by alternative parallel programming models and more complex system usage models.
Inside HPC – ARM HPC Panel with CCR Researcher Kevin Pedretti
The HPC news blog insideHPC recently posted a video of a panel session from the ARM Research Summit held in Cambridge, UK. The panel, “ARM in HPC – Software and Hardware Differentiation and Direction for Exascale and Beyond,” included CCR researcher Kevin Pedretti as well as other HPC leaders from industry and research labs.
Virtual Machine Support for the Cray XC
Researchers at Sandia National Laboratories have demonstrated for the first time the ability to deploy general purpose virtual machines on a Cray XC series supercomputer. Various high-performance computing and data intensive workloads exhibited near native levels of efficiency and scalability. This effort lays the groundwork for supporting coupled simulation and analysis applications that may require diverse operating systems and/or software stacks. In addition, virtualization may help increase developer and analyst productivity, easing the use of complex heterogeneous system resources.
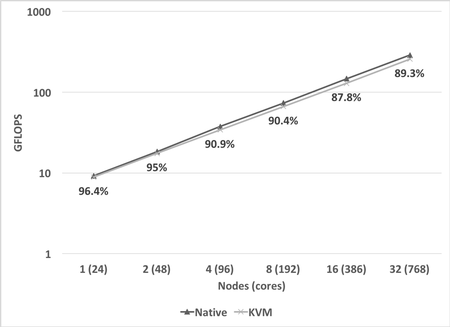
Performance Improvements for Open MPI Demonstrated at Scale on Trinity
Researchers from Sandia and Los Alamos National Laboratory recently collaborated to increase the performance of Open MPI on the Trinity supercomputer. The multi-lab team was able to significantly improve the performance of MPI remote memory access (RMA) operations, especially when RMA operations are used by multi-threaded applications. A key part of this work was the use of the RMA-MT benchmark developed at Sandia, which was used to identify and help diagnose performance bottlenecks and scalability limitations in Open MPI. The experiments that were run on the full scale of each partition of Trinity as part of this work represent the largest runs of the RMA-MT mode of MPI known to date. This collaboration was supported by the Computational Systems and Software Environment element of NNSA’s Advanced Simulation and Computing Program at each lab. The Trinity supercomputer is a result of the Alliance for Computing at Extreme Scale (ACES) partnership between Sandia and Los Alamos.
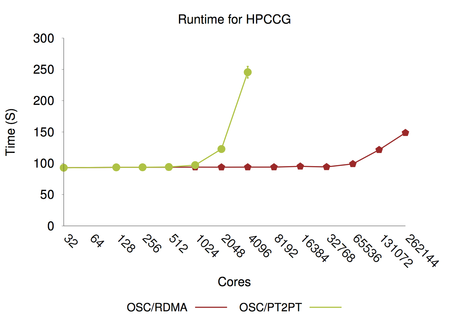
Copyright approval and open-source release of Implicit SPH (ISPH) software package.
The ISPH package solves large-scale multi-physics mesoscale flow problems using implicit smoothed particle hydrodynamics methods. It relies on an incremental pressure correction scheme (effective for flows with moderately small Reynolds numbers) and differential operator renormalizations to achieve second-order accuracy in both time and space. ISPH, built on LAMMPS and Trilinos, provides a massively parallel scalable simulation capability for incompressible, multiphase flow coupled with electrostatics. In particular, the code has been used to study pore-scale flows in a complex geometry discretized with 165M particles, electroosmotic flow and diffusive mixing of solute in micro channels. Results from these researches are published in 3 journal papers thus far. The code is available at https://github.com/kyungjoo-kim/implicit-sph.
CCR Researchers Co-Author Best Paper Nominee at IEEE DFT
CCR system software researchers Kurt Ferreira and Scott Levy are co-authors on the paper entitled “Lifetime Memory Reliability Data From the Field,” which has been nominated for Best Paper at the 2017 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT). The paper analyzes the fault rates from a large-scale high-performance computing system collected over five years. Data shows that the devices in the system did not show any signs of aging over the lifetime of the machine. In particular, the rate of DRAM memory errors did not change significantly. A better understanding of component failure rates is necessary to focus on effective mitigation strategies necessary to increase the reliability of leadership-scale computing platforms deployed by the DOE. IEEE DFT is an annual symposium that combines new academic research with state-of-the-art industrial data to explore manufacturing improvements in design, manufacturing, testing, reliability, and availability. This work was supported by NNSA’s Advanced Simulation and Computing program.
Dr. J. Brad Aimone selected to participate in the National Academy of Engineering’s 2017 US Frontiers of Engineering Symposium
Dr. J. Brad Aimone has been selected to participate in National Academy of Engineering’s (NAE) 23rd annual U.S. Frontiers of Engineering (USFOE) symposium. The 83 participants are among the nation’s most innovative young engineers who are performing exceptional engineering research and technical work in a variety of disciplines that will come together for the 2 1/2-day event. The participants are from industry, academia, and government and were nominated by fellow engineers or organizations. The 2017 USFOE will be hosted by United Technologies Research Center in East Hartford, Conn. and will cover cutting-edge developments in four areas: Mega-Tall Buildings and Other Future Places of Work, Unraveling the Complexity of the Brain, Energy Strategies to Power Our Future, and Machines That Teach Themselves. Dr. Aimone is currently working in the areas of theoretical neuroscience and neural-inspired computing. He has been leading the neural algorithms research team within Sandia’s Hardware Acceleration of Adaptive Neural Algorithms (HAANA) internal Grand Challenge LDRD, where he and others have been developing new brain-inspired approaches for next generation computing platforms.
CRADA Signed with Rigetti Quantum Computing RQC
Quantum computing researchers at Sandia National Laboratories have established a cooperative research agreement (CRADA) with Rigetti Quantum Computing (RQC), a Berkeley, CA based startup company. Sandia and RQC will collaborate to test and evaluate RQC’s 8-qubit quantum information processor. This collaboration will produce detailed, high-fidelity information about errors and fault mechanisms in quantum processors, which is critical to developing the next generation of quantum processors. Sandia and RQC each bring unique capabilities to the table, without which this R&D would be impossible. SNL’s unique and world-leading capabilities in qubit characterization include development of the open-source software pyGSTi for gate-set tomography (one of the most powerful protocols for characterizing qubits), while RQC is in the process of deploying a unique 8-qubit quantum processor whose performance may exceed that of existing devices. This CRADA will advance the state-of-the-art in qubit performance by leveraging these complementary capabilities.
Tenth Space Computing Workshop
The Center for Computing Research (1400) in collaboration with the Predictive Sensing Systems Group (6770) conducted the 10th annual Spacecraft Computing workshop May 30-June 2, 2017. The workshop, held at Sandia and a local hotel, focused on advanced computing for spacecraft, which require technology that functions reliably in the harsh and inaccessible environment of space. The workshop with an attendance of 80 included working groups and presentations from government, industry, and academia. The key topics this year included cyber security and novel processor designs, such as processor-in-memory, which would offer more throughput on a limited energy budget.
Slycat™ Expands User Community to Army Research Laboratory
Researchers at Sandia National Laboratories just completed an installation of SNL’s open-source ensemble analysis and visualization system, SlycatTM, at the Army Research Laboratory in Aberdeen, Maryland. This is the culmination of a year-long small project with the ARL that also includes a small amount of support funding for the remainder of FY17 and parts of FY18. Slycat™ will enable ARL users to remotely analyze large ensembles generated by simulation studies performed on Excalibur, a 3,098 node Cray XC40 system. This Slycat™ installation was challenging due to differences between how ARL and Sandia authenticate web-services, connect to High Performance Computing (HPC) platforms (especially in a Single Sign On environment), and launch parallel HPC jobs. As part of this work, the team modularized Slycat™ components to allow administrators to easily reconfigure the deployment configuration, switching between authentication mechanisms required by DOD, DOE, and other communities. These changes allow users outside of Sandia to utilize Slycat’s unique capabilities, increasing the impact of NNSA’s investment in Slycat™ by providing service in the national interest to DOD. (Summary: Researchers at Sandia have deployed the SlycatTM ensemble analysis and visualization system at the Army Research Laboratory.)
Sandia Releases Tempus Time Integration Library
A new time integration library has been open-source released under the Trilinos project. The Tempus library is being developed under the Exascale Computing Project/Advanced Technology Development and Mitigation (ECP/ATDM) program to support advanced analysis techniques, including Implicit-Explicit (IMEX) time integrators and embedded sensitivity analysis for next-generation code architectures. Tempus currently supports explicit Runge-Kutta 1-4th order and general tableau specification, implicit Runge-Kutta (DIRK) up to 5th order, and a Newmark-beta scheme to support second time derivatives. The code has been demonstrated in the Albany code base and is currently being integrated into the ATDM applications. Summary: Sandia has released a new library, Tempus, that provides core time integration algorithms for next-generation codes.
Mini-symposium on ice sheet modeling
At the SIAM CSE conference, a two part mini-symposium on Ice Sheet Modeling was organized by Sandians Luca Bertagna, Mauro Perego (1442) and Irina Tezaur (8759) along with Daniel Martin from LBNL. The mini-symposium focused on theoretical and computational advancements in ice sheet modeling, addressing many of the mathematical and computational challenges arising when modeling the dynamics of large ice sheets for computing projections of sea level rise. During the two lively sessions, a variety of topics were addressed by the speakers, including mesh adaptation, coupling of ice sheets and ocean, iceberg mélange and Bayesian inference. Bertagna, Hansen and Perego from SNL gave talks related to DOE’s PISCEES and FASTMath SciDAC projects.
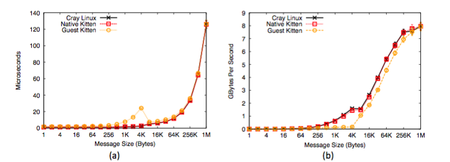
Kitten OS Demonstrates Near-Native Network Performance on Cray Aries Interconnect
One of the challenges in designing, developing, and deploying a research operating system (OS) for high- performance computing platforms has been the integration of device drivers for peripheral hardware, such as disk drives and network adapters. Developing and maintaining a device driver, which essentially allows the operating system to make use of the attached hardware, can be a tedious and time- consuming activity. Since nearly all vendors provide Linux device drivers for their hardware, it would be ideal if research OSs could simply use these existing drivers. Recently Sandia researchers along with collaborators from the University of Pittsburgh have successfully employed a multi-kernel approach that eliminates the need for a custom OS to have a custom device driver. The Kitten Lightweight Kernel OS was ported to the Cray XC architecture by extending the Cray Linux Environment to partition a node’s resources to be able to run Kitten alongside Linux. To enable applications running on Kitten to use Cray’s Aries interconnect, an approach was developed that passes control plane operations from Kitten to the Aries device driver running on Linux. Data plane transmissions flow directly from Kitten application memory to the Aries, enabling near-native MPI networking performance. Performance tuning is underway to try to optimize remaining performance differences.
5th Annual NICE Workshop
Neural computing researchers at Sandia National Laboratories helped organize and facilitate the 5th Neuro-Inspired Computational Elements (NICE) Workshop at IBM Almaden in San Jose, CA. The meeting was attended by neural computing researchers from numerous universities, computing software and hardware companies, and national laboratories (including LLNL, LANL, and Oak Ridge). There was also a notable presence of international efforts in neural computing, including the leaders of the two neuromorphic EU Human Brain Project efforts as well as representatives from DOE, NSF, and DARPA. Sandia had four talks and a number of posters focused on topics including brain-inspired adaptive algorithms, neural learning theory, and neural hardware evaluation methods.
USACM Thematic Workshop on Uncertainty Quantification and Data-Driven Modeling
The U.S. Association for Computational Mechanics (USACM) Thematic Workshop on Uncertainty Quantification and Data-Driven Modeling was held on March 23-24, 2017, in Austin, TX. The organizers of the technical program were James R. Stewart of Sandia National Laboratories and Krishna Garikipati of University of Michigan. The organization was coordinated through the USACM Technical Thrust Area on Uncertainty Quantification and Probabilistic Analysis. The purpose of this workshop was to bring together leading experts in uncertainty quantification, statistics, computer science, and computational science to discuss new research ideas in data-driven modeling. A total of 90 people attended, and the workshop included 20 talks and 34 posters. DOE’s Office of Advanced Scientific Computing Research provided financial support for students and postdocs to attend the workshop. A total of 10 postdocs and 27 graduate students, from 19 different (U.S.-based) institutions, received this support.
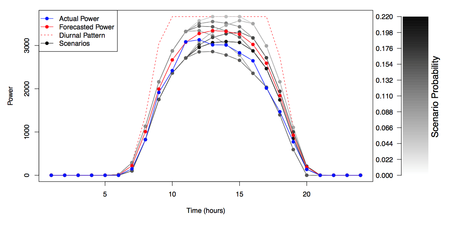
Enabling Very High Renewables Penetration on the Electric Power Grid
As part of DOE/ARPA-e’s NODES (Network Optimized Distributed Energy Systems) program, researchers at Sandia National Laboratories – with partners at Arizona State University and Nexant, Inc. – are working to develop advanced optimization algorithms for power grid operations, which directly account for uncertainty associated with forecasts of renewables (e.g., wind and solar) power production. By modeling and addressing such uncertainty directly, power systems operations will be able to integrate very large (>50% penetration levels) quantities of renewable energy, in a reliable and cost-effective manner. Feasibility studies are being conducted on real models of large-scale power system operators, including the Midwest Independent System Operator (MISO) and the Pennsylvania-Jersey-Maryland (PJM) system operator. (Summary: Researchers at Sandia National Laboratories, with partners at Arizona State University and Nexant Inc., are developing advanced strategies for enabling cost-effective and reliable integration of very large quantities of renewables power on the electric power grid.)
Research from Sandia shows brain stimulation during training boosts performance
Demonstration by Sandia National Laboratories helps to improves cyber training
Sandia National Laboratories (Sandia), a partner to Team Orlando, hosted a three-day demonstration of Sandia’s Information Design Assurance Red Team (IDART™) training capability on Jan. 31-Feb. 2. The goal of the demonstration was to determine whether Team Orlando could expand its relationship with Sandia to include IDART training for the services.
Sandia’s William Atkins and Benjamin Anderson presented the IDART™ training capability to several members of Team Orlando, DoD personnel, and guests from other government agencies. It introduced them to two of IDART’s training courses – Red Teaming for Program Managers (RT4PM) and the IDART Methodology. The first half-day was used to introduce and discuss RT4PM, which is designed to train program managers on when to use, or not use, a red team, and how to use that team effectively. The remaining time was spent on the IDART Methodology course, which describes the process used in an IDART assessment, and includes practical exercises that guide the students through an assessment scenario.
Integrated into the demonstration was a discussion on how the training could be leveraged by the services, and how Team Orlando could work with Sandia to deliver the training to a larger audience.
Sandia’s IDART has been performing assessments since 1996 for a variety of customers including government, military, and industry. Through its participation in a variety of government programs and leadership of industry conferences, the IDART team has assembled a broad vision of the use and practice of red teaming.
“This allows Team Orlando to do red team training for the services, leveraging methodology that is government owned,” said Dan Torgler, JTIEC deputy director and lead for Team Orlando’s cyber team. “It helps us develop our cyber capability and it also helps Sandia’s red team by off-loading most of their general services training so they can concentrate on vulnerability assessments and red teaming large systems. Then when there is something new or very specialized, we would come back together as a team to update the training.”
Sandia National Laboratories is one of 17 Department of Energy national labs. Although the Team Orlando and Sandia relationship is in development, it holds potential national security benefits through future training that could be part of Team Orlando’s capability portfolio in cyber, said Sandia’s Elaine Raybourn, who is a Team Orlando cyber team member.
“It’s been a short time since the training capability demonstration and we’re already seeing great success,” said Raybourn. “The Marine Corps has already adopted the template for training and is modifying it for their purposes. And we expect soon to see additional agreements between Sandia and Team Orlando that can facilitate our relationship in building a cyber portfolio.”

Climate
[From 2017 Sandia Labs Accomplishment Magazine]
As part of the five-year multi-institution DOE/SciDAC project PISCEES, Sandia has developed a land-ice simuluation code that has been integrated into DOE’s Accelerated Climate Model for Energy earth system model for use in climate projections. The Albany/FELIX code enables the calculation of initial conditions for land-ice simulations, critical for stable and accurate dynamic simulations of ice sheet evolution and the quantification of uncertainties in 21st century sea level rise. With NASA, the team has successfully validated simulations in comparison to actual Greenland ice sheet measurements.
Standardizing Node Memory Management for HPC
Computer scientists at Sandia National Laboratories are contributing to standardization of memory management interfaces for HPC applications through the OpenMP Language Committee. The emergence of multiple levels of memory with distinct characteristics (e.g., high bandwidth or persistent storage) is a disruptive technology change presenting both challenges and opportunities for DOE applications. OpenMP is the cross-vendor industry standard for shared memory parallel programming, making it an ideal forum to develop a portable solution to address this technology change, one that will allow applications to leverage these new memory types rewriting their code for each specific platform. For example, applications will be able to use the high bandwidth memory on nodes of the Trinity and Sierra supercomputers and later run the same codes on future machines. A technical report on the OpenMP web site details progress on this work: http://www.openmp.org/wp-content/uploads/openmp-TR5-final.pdf.
Improving Application Resilience to Memory Errors with Lightweight Compression
Researchers at Sandia National Laboratories have developed an application-independent library that can dramatically improve application performance by transparently correcting detected uncorrectable memory errors using lightweight compression mechanisms. Resilience to memory errors is identified by the Department of Energy (DOE) as a key challenge for next-generation, extreme-scale systems. Future systems are projected to contain many petabytes of memory. In addition to the sheer volume of the memory required, device trends, such as shrinking feature sizes and reduced supply voltages, have the potential to significantly increase the frequency of memory errors. Using a number of key workloads critical to DOE, our results demonstrate the potential of this technique at transparently correcting errors in memory without application intervention and to speed up application time-to-solution by over a factor of two in comparison to the current state-of-the-art checkpoint-based approaches.
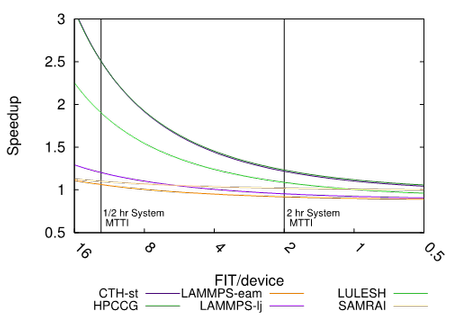
CCR Researchers Co-Author Best Student Paper Nominee at SC’16
CCR system software researchers Scott Levy, Kurt Ferreira, and Patrick Widener were co-authors on the paper entitled “Understanding Performance Interference in Next-Generation HPC Systems,” which was nominated for Best Student Paper at the 2016 ACM/IEEE International Conference on High-Performance Computing, Networking, Storage, and Analysis (SC’16). The paper presented a new stochastic modeling approach to help understand, characterize, and predict the impact of activities that can interfere with the progress of a computation. The lead author on the paper is Oscar Mondragon from the University of New Mexico, who performed this research under the Hobbes project, which was led by Sandia and funded by the Office of Advanced Scientific Computing Research in the DOE Office of Science.

ASCR Discovery Features CCR Exascale System Software Research
The January 2017 feature article of ASCR Discovery highlights exascale system software research led by the Center for Computing Research. The article “Upscale Computing: National labs lead the push for operating systems that let applications run at exascale,” discusses some of the exascale computing challenges from the operating system and runtime system perspective and the approach that two recent ASCR research projects, Hobbes and XPRESS, are taking to address these challenges. ASCR Discovery is an online magazine that publishes original articles about research projects sponsored by the Office of Advanced Scientific Computing Research in the DOE Office of Science.

Andrew J. Landahl elected a Fellow of APS
Andrew J. Landahl, a distinguished member of the Non-conventional Computing Technology department, was elected a Fellow of the American Physical Society (APS). He was nominated by the Topical Group on Quantum Information (GQI), which is a segment of APS of which Andrew is a recent past-Chair. The citation for his Fellowship reads, “For outstanding leadership of and conscientious service to the quantum information community; and pioneering contributions to quantum computing theory, including fault-tolerant quantum computing, quantum error correction, universal adiabatic quantum computing, and novel quantum search algorithms.” The APS Fellowship recognizes the foundational contributions that Andrew has made in several branches of quantum theory essential for making quantum information processing practical, in particular in fault tolerant architecture design and quantum error correction. This Fellowship is a prestigious recognition of Andrew by his peers; it is reserved for no more than one half of 1% of APS members in any given year. He will be presented with his Fellowship certificate at the annual meeting of the GQI at the APS March 2017 meeting. Andrew joined Sandia National Laboratories when he was recruited to lead the theory task in the Quantum Information Science and Technology (QIST) Grand Challenge research project (GC LDRD). He has since successfully proposed and then led the AQUARIUS GC LDRD, which focused on assessing the potential of adiabatic quantum computing, and is co-Deputy Director of Sandia’s Science and Engineering of Quantum Information Systems (SEQIS) research challenge.
Computer Magazine Highlights CCR Expertise in Energy Efficient HPC
The October 2016 issue of Computer magazine on Energy Efficient Computing contains three feature articles co-authored by Sandians, including two articles from staff in the Center for Computing Research. The article “Standardizing Power Monitoring and Control at Exascale” co-authored by Ryan Grant (1423), Michael Levenhagen (1423), Stephen Olivier (1423), Kevin Pedretti (1423), and Jim Laros (1422) describes the Power API project, while “Using Performance-Power Modeling to Improve Energy Efficiency of HPC Applications,” co-written by Jeanine Cook (1422), describes a framework for modeling power that considers application-specific data to predict power consumption. Computer magazine is the flagship publication of the IEEE Computer Society.

Trinity Program Pursuing “Power-Aware Scheduling” Through Contract with Adaptive Computing
The Trinity project has placed a new “Non-Recurring Engineering” contract with Adaptive Computing to develop “Power-Aware Scheduling” capabilities for the Trinity supercomputer, which when fully installed will consume 8-10 megawatts (MW) and have a peak computational capability of more than 40 petaflops. This work will enable power to be managed as a resource by the system’s workload manager and lead to better understanding of how to operate future ASC platforms to maximize the benefit derived from the available power budget. This is important because each generation of supercomputers is consuming significantly more power than the previous generation. Given practical limits on a system-level power budget of 20-40 MW, this trend is expected to cause power to become the primary constraint on supercomputer performance rather than the amount of computing hardware available. Therefore, power budgets must be managed as a first-class resource and distributed intelligently by the workload manager. Trinity project staff at SNL and LANL will be collaborating closely with Adaptive Computing to develop power-aware scheduling capabilities and exercise them at scale on Trinity. Some of the areas explored will include system-, job-, and component-level power budgeting, job scheduling within power budgets, user-interfaces for specifying power-related quality-of-service requirements, system power usage ramp rate control, and power usage reporting and billing. The work will leverage and interface with the Power API implementation and other advanced power management capabilities being developed by Cray for the Trinity platform. The overall insight gained from this work will be used to help specify the requirements and features needed on future supercomputer platforms.
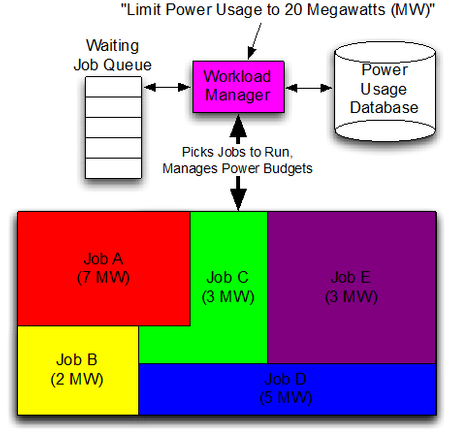
Performance Portable Sparse Matrix-Matrix Multiplication is significantly faster than vendor provided libraries
Sandia researchers developed a new algorithm for a performance-portable sparse matrix-matrix multiplication kernel in the KokkosKernels package. This new kernel is thread scalable, and memory-efficient in comparison to other publicly available implementations. It also optimizes for use cases from Sandia applications, such as reusing the symbolic structure of the problems for applications especially when the setup phase of multigrid methods is repeated more than once. The new Kokkos based implementation enables performance portability in GPUs, CPUs and Intel Xeon Phis. Currently the KokkosKernels SPGEMM routine is up to ~14.89x (5.39x on average) faster than NVIDIA’s cuSPARSE library routine on K80 GPUs. It also achieves 1.22x speedups (geometric mean) w.r.t. Intel’s MKL library routine on Intel’s Knights Landing (KNL). When the kernel can reuse the symbolic structure in multigrid multiplications it is 2.55x faster than Intel MKL library on Intel’s KNL. The memory-efficient algorithm also allows solving larger problems that cannot be solved by codes like NVIDIA’s CUSP library and Intel’s MKL when using larger number of threads.
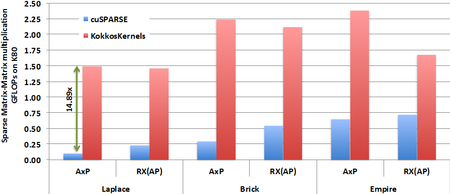
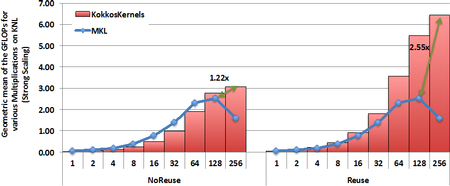
New ARIA Linear Solver for Coupled Multiphysics Flows
A new multigrid linear solver has been developed and deployed for ARIA, a finite element analysis code for the solution of coupled multiphysics problems. The new linear solver specifically addresses challenges associated with PDE simulations where the number of degrees-of-freedom at each mesh node varies. This scenario frequently arises within ARIA when representing fields with discontinuities at interfaces. The new iterative solver is able to main these interfaces throughout the internal multigrid hierarchy, which is critical to realizing the solver’s rapid convergence rates. On some problems, the new solver runs 10x faster than anything previously available to the ARIA team. One problem required 20 minutes to solve with the new solver, whereas the old solver did not converge in 10 hours. The ARIA team is currently utilizing and accessing the new solver for a broad range of applications such as Navy railgun applications, and NW applications including laser welding, thermal battery modeling, and environmental sensing devices.
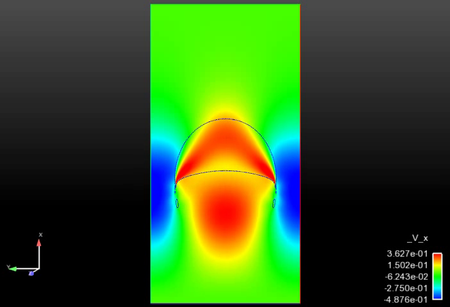
Improving Ice Sheet Models Through Algebraic Multigrid Methods
Evaluating the opportunities for multi-level memory
1420 researchers successfully completed a CSSE Level 2 milestone investigating the impact of next-generation multi-level memory hierarchies (i.e., hierarchies including multiple main memory technologies such as high-bandwidth memory and traditional DDR DRAM) on key ASC algorithms and kernels. The study found that while ASC applications vary widely in their ability to make use of higher-bandwidth memory, for some key kernels the high-bandwidth memory increases performance dramatically. Researchers also determined best-paths-forward for managing data movement and allocation between the multiple memory levels. This study will help to shape the use of impending and upcoming DOE procurements including the new Trinity platform. The study also added significant capability in the Structural Simulation Toolkit (SST), enabling node-level architectural simulation of larger-scale and complex codes. Two papers describing some of the results were published in the ACM MEMSYS 2016 conference. Full results were published in a SAND report.
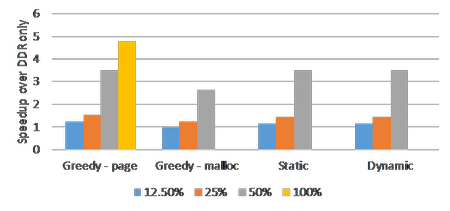
Sandians organize IMA Workshop “Frontiers in PDE-constrained Optimization”
Sandia researchers Drew Kouri (1441) and Denis Ridzal (1441) organized a five-day workshop on “Frontiers in PDE-constrained Optimization” at the Institute for Mathematics and Its Applications (IMA), in collaboration with Harbir Antil (George Mason University) and Martin Lacasse (ExxonMobil). The workshop brought together practitioners of PDE-constrained optimization from different disciplines, and provided a broad and uniform introduction of the topic to young researchers and students, including lectures taught by the organizers. The program included two days of advanced tutorials, followed by three days of invited talks, formal discussions and a poster session. Nearly sixty researchers from seven countries attended the workshop.
Refactored I/O Emulation Framework To Enable Customized Mini-app Generation
Researchers at Sandia are actively investigating methods to develop better understanding of the I/O performance characteristics of SIERRA applications, both to provide guidance for current application deployments and to help prepare for migrations to future hardware and software platforms. The MiniIO C++ programming framework has recently been refactored to provide developers with the capability to rapidly generate targeted emulations of I/O behavior. This capability is enabled through an extensible class hierarchy, and one of the goals of the framework is to incorporate subclasses to form a catalog of these targeted mini-I/O applications. The framework provides base classes which implement I/O patterns commonly found in production applications, and various data storage options are available or planned. The framework will be documented in a forthcoming SAND report.
Ray Tuminaro Co-Organized Fourteenth Copper Mountain Conference on Iterative Methods
Sandia co-sponsored and helped organize the most recent Copper Mountain Conference on Iterative Methods, an event that examined numerical analysis issues associated with linear algebraic approaches to numerical PDEs and data/graph analysis. The co-chairs for the conference were Ray Tuminaro (Sandia) and Michele Benzi (Emory). This prominent conference drew some 200 attendees, the largest number of participants in several decades and received a record 39 student competition entries. Associated with the conference, a special issue of the SIAM Journal on Scientific Computing will appear and has received 55 submissions (also a record number).
On-node Resource Management for Supercomputers
Researchers at Sandia National Laboratories are designing an integrated approach to resource management on the supercomputer node. Increasingly complex DOE applications and associated libraries create the problem of too many software components competing for shared on-node resources – system memory and processor cores on which to execute. Our resource management scheme will allow arbitration and tracking of resources to coordinate use of these resources, turning competition into cooperation. The approach combines interfaces to Sandia’s DARMA asynchronous many-task (AMT) software for policy decisions and to the Kokkos manycore performance portability library and Data Warehouse for resource deployment as clients of the resource manager.
GazeAppraise Team Receives Notable Technology Development Award
Technology Development Award: Sandia’s GazeAppraise team received a Notable Technology Development award from the Federal Laboratory Consortium (FLC) on Technology Transfer, Mid-Continent Region. The award for GazeAppraise Eye Movement Analysis Software was presented at the annual FLC regional meeting in Albuquerque, September 13-15, 2016. The Mid-Continent region includes 15 states. This year’s meeting was attended by representatives from DOE, DoD and other federal laboratories. The GazeAppraise team is: Mike Haass (1461); Laura McNamara (5346); Danny Rintoul (1462), Andy Wilson (1461) and Laura Matzen (1463).
New Eye Movement Analysis Technology: GazeAppraise software offers a new way to understand human performance as it relates to analysis of dynamic soft-copy images on computer screens. The visual cognition research community lacks software that models how our eyes dynamically recalibrate their trajectory when tracking a moving target across a scene and GazeAppraise is strong at characterizing those “smooth pursuit” eye movements. It has opened up entirely new ways of evaluating search strategies in a wide range of problem areas.
Insights discovered through the use of GazeAppraise will be incorporated into next-generation analysis hardware and software systems. These systems will be used to improve human performance in dynamic image analysis applied to medical diagnostics, airport security, nuclear nonproliferation, and any area where people are working with soft-copy images.
Partnerships Formed: The partnerships the Sandia team has developed create interaction between behavioral scientists, computer scientists, and specialists in other fields, enriching eye tracking research and applications.
Partnerships with two academic partners, Georgia Tech (GT) and the University of Illinois at Urbana-Champaign (UIUC), help Sandia to fine tune the quality of the technology and algorithms in GazeAppraise. The work Sandia and the university partners are doing will be an important part of eye movement research. GT is helping with the value framework that can be used to evaluate information displays. UIUC, with an interdisciplinary team, is helping with image-driven visual saliency and goal-directed visual processing.
A cooperative research and development agreement (CRADA) with EyeTracking, Inc., a company specializing in this field, gives the Sandia team access to a wide array of eye tracking systems and a pathway to commercial applications for this planned technology transfer.
GazeAppraise team nominated for federal labs consortium notable technology development award
Overview
Experienced professionals, whether in security or medicine, are great at pattern recognition and spotting irregularities as they scan images, but can be overwhelmed by the volume of data, especially in rapidly changing and high-stress environments. New products have been developed to assist workers, but it’s unclear that these products actually help them scan images more effectively.
Eye tracking data and information can help researchers and practitioners organize new image products in ways that demonstrably support effective signature detection, while making visual scanning workflows more comfortable and efficient for the people doing them.
GazeAppraise software is an eye tracking analysis solution that offers a new way to understand human performance as it relates to analysis of dynamic soft-copy images on computer screens. Current eye tracking analysis tools support limited comparisons of gaze patterns across a group of individuals viewing soft-copy images on computer screens. Existing tools allow for comparison of either spatial, or temporal (time sequence) characteristics of gaze patterns independently. But because of this unidimensional approach, rich comparisons of whole scan paths are not possible. For example, existing analysis packages cannot automatically identify different scanning strategies such as spiral gaze patterns or rastering the eyes across an image from left to right and top to bottom. GazeAppraise takes into account BOTH the spatial and temporal information contained in scanpaths and automatically identifies common scanning strategies across a group of individuals. With GazeAppraise, researchers, marketers, or anyone who designs human information interaction systems, will be able to understand how people move their attention across information displays and how to optimize those systems to increase human performance. It has opened up entirely new ways of evaluating search strategies in a wide range of problem areas.
Insights discovered through the use of GazeAppraise will be incorporated into next-generation analysis hardware and software systems. These systems will be used to improve human performance in dynamic image analysis applied to medical diagnostics, airport security, nuclear nonproliferation, and any area where people are working with soft-copy images.
Description of technology
Using a unique algorithm, GazeAppraise offers a new way to understand human performance as it relates to analysis of dynamic soft-copy images. Researchers have excellent tools for analyzing human gaze patterns as people are interacting with static stimuli—for example, when reading a line of text or examining a natural scene. However, the visual cognition research community lacks algorithms and software that enable us to model how our eyes dynamically recalibrate their trajectory when tracking a moving target across a scene.
The GazeAppraise software algorithm is strong at characterizing those “smooth pursuit” eye movements; in doing so, it has opened up entirely new ways of evaluating search strategies in a wide range of problem areas, across a wide range of gaze datasets. This is because most eye tracking datasets are analyzed using standard statistical models to reduce the raw data to a small number of points, called fixations, where a person’s eyes came to rest on a specific part of an image. In contrast, GazeAppraise starts with the scanpath that represents the movement of human gaze over an entire image or target. GazeAppraise interprets collections of eye movements as whole shapes, with geometric features (such as length, angularity, aspect ratio, etc.) that can be used to differentiate and classifying variations in eye movement patterns among individuals and across different image sets. It can categorize scanpaths from raw eye tracking data, even when those data include samples collected with variations in calibration precision, tracking consistency, and viewer performance. Evaluating collections of eye movements as a holistic pattern, rather than a set of discrete spatiotemporal events, provides insight into the strategies of experts as they try to gain information from dynamic imagery display systems—not only with moving targets, but in still scenes as well.
Partnerships formed
The partnerships the Sandia team has developed create interaction between behavioral scientists, computer scientists, and specialists in other fields, enriching eye tracking research and applications.
Partnerships formed under Sandia’s Academic Alliance program with two academic partners, Georgia Tech (GT) and the University of Illinois at Urbana-Champaign (UIUC), help Sandia to fine tune the quality of the technology and algorithms in GazeAppraise. The work Sandia and the university partners are doing will be an important part of eye movement research. GT is helping with the value framework that can be used to evaluate information displays. UIUC, with an interdisciplinary team, is helping with image-driven visual saliency and goal-directed visual processing.
A cooperative research and development agreement (CRADA) with EyeTracking, Inc., a company specializing in this field, gives the Sandia team access to a wide array of eye tracking systems and a pathway to commercial applications for this planned technology transfer.
The GazeAppraise team is Mike Haass, Laura McNamara, Mark Danny Rintoul, Andy Wilson, and Laura Matzen.
ECP/HT PathForward RFP
On June 16, 2016 the DOE Exascale Computing Project issued a RFP for Vendor node and system design R&D projects. Proposals were received on July 18, 2016. The PathForward RFP seeks hardware node and system design solutions that will improve application performance and developer productivity while maximizing energy efficiency and reliability of an exascale system. PathForward objectives are to support Hardware R&D that will:
- Substantially improve the competitiveness of the HPC exascale system proposals in 2019, where application performance figures of merit will be the most important criteria.
- Improve the Offeror’s confidence in the value and feasibility of aggressive advanced technology options that they are willing to propose for the HPC exascale system acquisitions.
- Identify the most promising technology options that would be included in 2019 proposals for the HPC exascale systems.
The current plan is for a six-lab ECP team to complete a review of the PathForward technical and cost proposals, and to complete source selection by mid-August.
1460 researchers awarded contract to provide test and evaluation for IARPA MICrONS Program
1460 researchers recently won a contract to provide test and evaluation support for a new IARPA program: Machine Intelligence from Cortical Networks (MICrONS). The MICrONS program aims to advance a new generation of neural-inspired machine learning algorithms by reverse engineering the algorithms and computations of the brain. The Sandia team’s efforts will include applying sensitivity analysis to validate computational neural models, developing novel challenge stimuli and evaluation metrics to assess the performance of novel machine learning algorithms, and designing evaluation methodologies for assessing computational neural model designs and the neural fidelity of machine learning algorithms. This work will book through the Defense Systems and Assessments PMU and supports the Synergistic Defense Products Mission Area.
The Sandia team is highly interdisciplinary and includes computational neuroscientists (a growing capability within 1460) as well as researchers from existing 1460 strengths in machine learning, data analytics, and computation. The team includes (in alphabetical order):
PI and POC: Frances Chance (1462)
Brad Aimone (1462), Kristofor Carlson (1462), Brad Carvey (1461), Warren Davis (1461), Michael Haass (1461), Jacob Hobbs (6132), Kiran Lakkaraju (1463), Kim Pfeiffer (1720), Fred Rothganger (1462), Timothy Shead (1461), Craig Vineyard (1462), Christina Warrender (1461)
Multi-threaded MPI Remote Memory Mini-applications at Scale
ACES researchers have used mini-applications utilizing next generation communication techniques, remote memory access with multi-threading, the only RMA-MT mini-applications currently available and demonstrated their performance at full scale on Trinity. Initial results are promising and are scaling well. Improvements have been made to Open MPI in response to these mini-applications and initial scaling results that are showing promise for future testing on real applications. Initial results on smaller systems show that Open MPI is performing well in comparison to other MPI implementations.
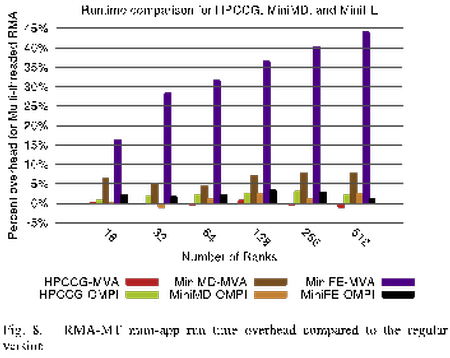
Memristor Simulator Aids Synthesis of Efficient Devices
Denis Mamaluy (1425) and Xujiao (Suzey) Gao (1355)
Memristors are variable resistors that can be adjusted, reversibly, by applied current. They are one of the strongest candidates to replace flash memory, and possibly DRAM and SRAM in the nearest future. Memristors also have a high potential as a beyond-CMOS technology for logic circuits in novel architectures for high performance computing. In order to aid in the on-going Sandia memristor fabrication efforts and establish clear physical picture of resistance switching in different types of transition metal oxide (TMO) memristors, we are creating a Memristor Charge Transport Simulator (CIS LDRD 173024), based on Sandia’s Charon device simulator code. The Simulator helps to facilitate understanding of switching mechanisms, predict electrical characteristics, and aid Sandia experimentalists in device optimization for different applications. Switching in these devices involves a complex process of oxygen vacancy motion in the TMO film, governed by temporally and spatially intertwined, thermally and electrically driven processes. Thus, computational simulation of these phenomena required a new approach that captures effects of many species transport (ions/vacancies/electrons/holes), changes in material composition, Fickian diffusion, thermophoresis, and electric field drift. Recently we obtained the first practical results for a representative group of TaOx devices, including a semi-quantitatively accurate characteristic hysteresis I-V curves (current-voltage) that reflects the memristive properties of these devices (Figure 1). (Quantitative comparison with experiment awaits further acquisition of the fundamental material properties.) These results confirm the experimental hypothesis that TaOx memristors belong to bipolar-type devices that are strongly influenced by both the electric field and thermal effects (see “type b” in Figure 2). They also demonstrate the capability and value of the Memristor Simulator. The Simulator will now be used to determine the threshold between thermally driven (high power) and electrically driven (low power) TaOx device geometries to select structures best suitable for neuromorphic applications.
![Figure 2. Schematics of conduction channels (red) in switching matrix materials (blue) in four (a-d) types of switching devices, where both electric field and Joule heating drive the switching. The grey arrows indicate the idealized ionic motion. The inset to each schematic shows typical switching current–voltage curve. [J.J.Yang et al., Nature Nanotechnology 8, 13 (2013)].](https://www.sandia.gov/app/uploads/sites/210/2022/06/Figure2_Mamuluy_450.jpg)
Joint Position in Scalable Computing R&D with UNM
The Center for Computing Research (CCR) is pleased to announce a job opening for a joint position with the University of New Mexico (UNM) in Scalable Computing R&D. The CCR seeks qualified candidates to help establish a strong collaboration with UNM in the area of Scalable Computing research and development. The successful candidate will have an opportunity to be considered for a joint position where he/she could concurrently hold a part-time position of Joint University Faculty Research Scientist at Sandia and a part-time faculty appointment in a tenure or tenure tracks with the Computer Science Department at UNM. The technical emphasis of the research collaborations will be in extreme-scale scientific computing and data analysis, including: execution models; programming languages and productivity tools; scalable algorithm design and implementation; operating and runtime system software; high— performance I/O, communication, and storage; data analysis and visualization; and scalable computer hardware architecture.
Click on the “Careers” link above and search for Job Posting 653430 for more details.

High-Accuracy Calculations of 2-D Semiconductor, Phosphorene
Luke Shulenburger (1641) and Andrew Baczewski (1425)
Recently, we published work in Nano Letters (Impact Factor 13.592) detailing the results of quantum Monte Carlo (QMC) calculations from our BES-funded investigation of the properties of phosphorene, a single-layer form of black phosphorus [1]. Black phosphorus is a layered form of phosphorus in which highly anisotropic 2D sheets are held together by strong covalent bonds, and stacks of these sheets are nominally held together by the van der Waals’ interaction [2]. A single layer of black phosphorus can be exfoliated yielding phosphorene, a material experiencing intense research for applications in electronics due to its direct band gap, high carrier mobility, and strain-sensitivity [3]. The relationship between phosphorus and phosphorene, is analogous to that of graphite and graphene, however, graphene has no band gap, which has impeded some electronics applications. Our QMC calculations indicate that we can accurately compute experimentally measured structural parameters of the bulk system [2], giving us confidence in our predictions of the as-yet-unmeasured single- and few-layer structure and the exfoliation energy required to mechanically remove a single sheet of phosphorene. We also predict that stacking fault defects will be energetically unfavorable in few-layer preparations of phosphorene. As few-layer phosphorene is also of interest for applications, this is critical enabling information for experiment.
One unexpected outcome of our study was uncovering a previously unknown inaccuracy in Density functional theory (DFT). DFT is, by far, the most popular ab initio electronic structure method for materials science. However, while our QMC calculations predict significant charge reorganization in going from single- to few-layer phosphorene, or single-layer phosphorene to bulk black phosphorus, DFT completely fails to predict any charge reorganization. This deficiency appears to be a feature of all currently existing exchange-correlation functionals, the key approximation in DFT. As QMC is a more accurate electronic structure method, barring discovery of an error in our implementation and execution, we expect that our results will provide an invaluable data point for physicists, chemists, and materials scientists interested in developing better functionals.
The expectation that our QMC calculations are worthy of this benchmark status is born of the nature of these calculations, which involve the direct statistical sampling of high dimensional, many-body quantum mechanical quantities. These calculations are computationally very intensive; this entire study consumed approximately 20 million CPU hours split between Mira at ANL’s LCF and Sequoia at LLNL. This work was in collaboration with David Tománek’s group at Michigan State University.
[1] L. Shulenburger, et. al., “The Nature of the Interlayer Interaction in Bulk and Few-Layer Phosphorus”, Nano Letters, 2015.
[2] L. Cartz, et. al., “Effect of pressure on bonding in black phosphorus”, The Journal of Chemical Physics, 1983.
[3] H. Liu, et. al., “Phosphorene: An Unexplored 2D Semiconductor with a High Hole Mobility”, ACS Nano, 2014.
Forecasting, Not Fearing, Sea-Level Rise
Accelerating development of semiconductor qubits through better computational modeling
John King Gamble and N. Tobias Jacobson Non-Conventional Computing Technologies Center for Computational Research
NiMC: Network-Induced Memory Contention
Researchers at Sandia National Laboratories have introduced the concept of Network-Induced Memory Contention (NiMC) and demonstrated its impact for a variety of current HPC system architectures. NiMC occurs when a remote direct memory access (RDMA) contends with the target node for the target’s memory resources. Given the importance of computation/communication overlap in future systems, this research explores the hidden cost of RDMA network traffic creating memory contention with running applications. It has been shown that NiMC is a concern for both onloaded and offloaded networking hardware, with the onloaded hardware observing the largest performance impact of up to 3X performance degradation for the molecular dynamics simulator LAMMPS at 8,192 cores when traffic of RDMA creates contention at endpoints. This work has offered three solutions to NiMC, each applicable for different intensities of RDMA traffic, that can reduce the overheads associated with memory contention to only 6.4% versus the 300%+ originally observed.
(Summary: Researchers at Sandia have been the first to investigate the impact of RDMA networks on application memory bandwith on modern systems.)
Publications: SAND2016-0028 C: Taylor Groves, Ryan E. Grant, Dorian Arnold, 2016, “NiMC:Characterizing and Eliminating Network-Induced Memory Contention”. 30th IEEE International Parallel & Distributed Processing Symposium (IPDPS 2016), IEEE, New York, NY, USA, 10 pages (Accepted)
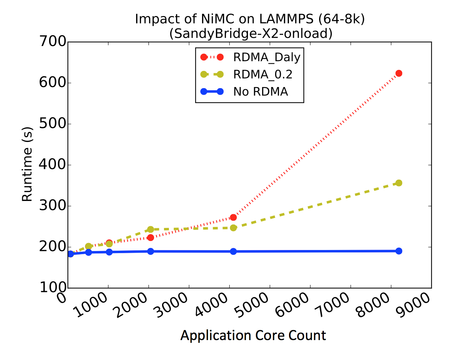
Kitten Lightweight Kernel Booting on Intel Knights Landing processor and Running HPX-5 Many-Task Runtime System
Sandia’s Kitten Lightweight Kernel operating system has been ported to a pre-production Intel Knights Landing system and demonstrated running the XPRESS system software stack on the “many-core” system’s 240 available hardware contexts (Figure 1). The demo was presented at a recent DOE ASCR X-Stack Program Principal Investigator Meeting and consisted of the Kitten Lightweight Kernel booting, detecting and initializing all of the system’s cores and memory, and then starting the HPX-5 version of the LULESH benchmark. As a demonstration of the RCR power monitoring agent and APEX policy engine developed by the XPRESS project, the demo showed a user-defined power constraint being enforced by dynamically changing the number of active hardware contexts based on observed power usage, highlighting the dynamic adaptive capability of the XPRESS system software stack.
In situ visualization on the Mutrino Trinity Platform
Sandia visualization researchers have collaborated with engineers from Sandia’s SIERRA Toolkit-based Nalu low Mach flow code team to integrate the ParaView/Catalyst in situ visualization library with the Nalu code. In situ visualization allows parallel simulations to perform analysis and visualization at run time in order to avoid lengthy I/O operations required for traditional post-processing analysis and visualization. The team has demonstrated Nalu with Catalyst on up to 80 nodes (2560 cores) of the Trinity-development system Mutrino in preparation for larger runs of up to 60,800 cores on the Trinity machine. The output files generated by Catalyst are used to study post-stall performance of wind turbine airfoils. (POC, Thomas Otahal and Ron Oldfield)
Cindy Phillips Named as New Fellow of SIAM
Sandia researcher Cindy Phillips has been selected as a Fellow by the Society for Industrial and Applied Mathematics (SIAM), the leading professional organization for applied and computational mathematicians. Cindy was recognized for “Contributions to the theory and applications of combinatorial optimization.” Selection as a SIAM fellow is an honor the society reserves for its most distinguished and accomplished members.
Cindy is a Senior Scientist in the Center for Computing Research, and she works on combinatorial optimization, algorithm design and analysis, and parallel computation. Her research has touched on a wide range of applications including scheduling, network and infrastructure surety, integer programming, graph algorithms, computational biology, quantum computing, computer security, wireless network management, social network analysis/graph data mining, sensor placement, and co-design of algorithms for next generation architectures. Her research has been honored with a number of international awards. Cindy received a bachelor’s degree in applied mathematics from Harvard University and a PhD in computer science from Massachusetts Institute of Technology. She has been at Sandia since 1990.

Aeras Project Develops Next-Generation Atmosphere Model
The goal of the Aeras LDRD project is to develop a next-generation atmosphere model suitable for a global climate model, with advanced capabilities such as performance portability and embedded uncertainty quantification (UQ). Performance portability will allow us to run our code very efficiently on a diverse set of current and future computer architectures (such as GPUs or threaded CPUs) without a laborious porting process. Our particular approach to embedded UQ takes advantage of running ensembles of simulations to achieve speedups.
Recently, we completed initial development of the 3D hydrostatic equations, which are the target equations for the atmosphere in climate, and a hyperviscosity implementation, which is the preferred method for stabilizing our spectral element discretization. These implementations are currently undergoing rigorous and methodical testing.
The 2D shallow water equations (applied to air, not water) for the global atmosphere were implemented previously and have already demonstrated the project’s next-generation capabilities. We see a roughly 9 times performance increase using threaded CPUs and up to 24 times performance increase with GPUs when the amount of computational work is sufficient. Our approach for computing ensemble samples concurrently can add up to 2 times performance increase when running as few as four samples concurrently. We expect to see similar results for 3D when the hydrostatic equations are ready for performance analysis.
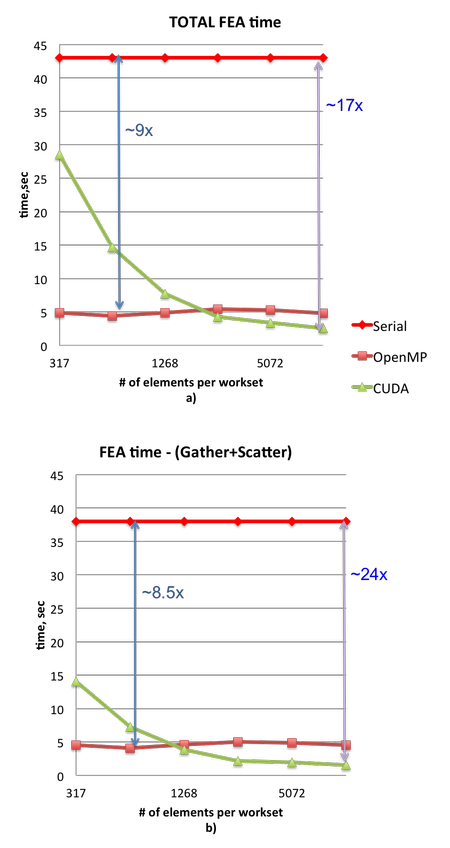
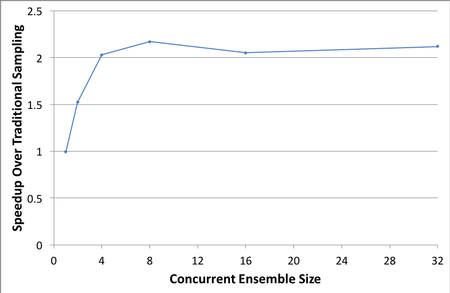
A new, optimization-based coupling strategy for nonlocal and local diffusion models
The use of nonlocal models in science and engineering applications has been steadily increasing over the past decade. The ability of nonlocal theories to accurately capture effects that are difficult or impossible to represent by local partial differential equation (PDE) models motivates and drives the interest in a wide range of alternative nonlocal models. For instance, nonlocal continuum theories such as peridynamics or physics-based nonlocal elasticity allow interactions at distance without contact and can accurately resolve small scale features such as crack tips and dislocations. However, the improved accuracy of nonlocal models comes at the price of a significant increase in computational costs compared to, e.g., traditional PDEs. In particular, a complete nonlocal simulation remains computationally untenable for many science and engineering applications. Further, nonlocal models generally require the application of volume constraints, which are more difficult to specify in practice than the boundary conditions of the local theory. As a result, many researches have focused attention on the development of various Local-to-Nonlocal coupling strategies, which aim to combine the accuracy of nonlocal models with the computational efficiency of PDEs. The basic idea is to use the more efficient PDE model everywhere except in those parts of the domain that require the improved accuracy of the nonlocal model.
Sandia researchers have recently developed a new, optimization-based method for the coupling of nonlocal and local diffusion problems. The approach formulates the coupling as a control problem where the states are the solutions of the nonlocal and local equations, the objective is to minimize their mismatch on the overlap of the nonlocal and local domains, and the controls are virtual volume constraints and boundary conditions. The new coupling approach is supported by rigorous mathematical theory establishing the well-posedness of the optimization formulation. Sandia researchers have implemented and demonstrated the optimization coupling approach using Sandia’s agile software components toolkit; the latter provides the groundwork for the development of engineering analysis tools.

A new optimization-based mesh correction method with volume and convexity constraints.
Mesh motion is at the core of many numerical methods for time dependent flow and structure problems. Examples include Lagrangian hydrodynamics methods, in which the mesh evolves with time in order to track deformations of the problem domain, and the related Arbitrary Lagrangian-Eulerian methods, which incorporate a mesh rezoning step to mitigate excessive mesh deformations and mesh tangling. Another important example are semi-Lagrangian methods for advection problems, including schemes utilizing incremental remapping as a transport algorithm. These methods require computation of the mesh motion under a velocity field; most of them approximate the deformed Lagrangian mesh by solving numerically the kinematic relation to estimate the new cell vertex positions and connecting them by straight lines. Consequently, the cells in the deformed mesh incur two types of errors: one due to the approximation of the vertex trajectories and another due to the approximation of the deformed cell edges by straight lines. These temporal and spatial errors yield approximate Lagrangian cells whose volumes do not match the volumes of the exact Lagrangian cells and may compromise the accuracy of numerical methods relying on mesh motion.
A recent collaboration between researchers at Sandia National Laboratories and Los Alamos National Laboratories has led to the development of a new, optimization-based method for volume correction, which is applicable in multiple modeling and simulation contexts ranging from Lagrangian methods to mesh quality improvement. Their approach considers the problem of finding a mesh such that 1) it is the closest, with respect to a suitable metric, to a given source mesh having the same connectivity, and 2) the volumes of its cells match a set of prescribed positive values that are not necessarily equal to the cell volumes in the source mesh. This volume correction problem is then formulated as a constrained optimization problem in which the distance to the source mesh defines an optimization objective, while the prescribed cell volumes, mesh validity and/or cell convexity specify the constraint. The optimization problem is solved numerically by a sequential quadratic programming (SQP) algorithm whose performance scales with the mesh size. The scalable performance is achieved by developing a specialized multigrid-based preconditioner for optimality systems that arise in the application of the SQP method to the volume correction problem. Preliminary numerical studies demonstrate the accuracy and robustness of the new method.


A Lightweight Trilinos Solver Interface for Fortran-Based Multiphysics Applications
Sandia researchers have previously developed a lightweight interface software layer that makes linear solvers from the Sandia Trilinos project accessible to the Fortran-based multiphase flow solver suite named MFIX (https://mfix.netl.doe.gov), originally developed by the National Energy Technology Laboratory (NETL). Under a current Office of Fossil Energy project named “MFIX-DEM Phi”, we are optimizing this interface to improve the time-to-solution for various complex multiphase flow simulations such as fluid phase with multiple distinct particles (Eulerian-Lagrangian approach) and multiple fluid phases (Eulerian-Eulerian approach). In particular, the goal is to improve time-to-solution for simulations such as that depicted in the accompanying image, which shows first-of-its-kind industrial scale gasifier simulations performed as part of an NETL 2008-2010 INCITE award. It is anticipated that this software interface will be publicly released in 2016.
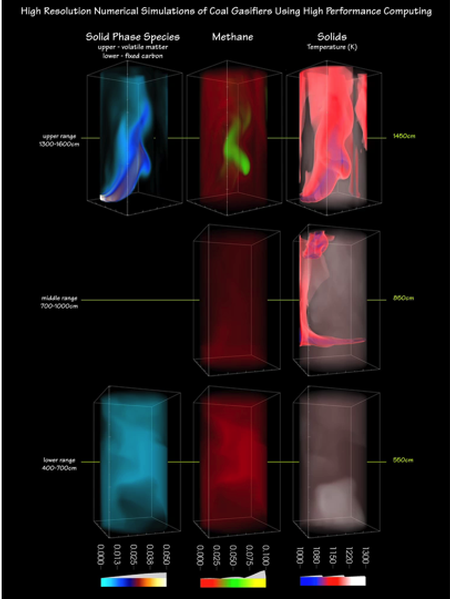
Addressing Challenges in Reduced-Order Modeling
https://sinews.siam.org/DetailsPage/tabid/607/ArticleID/745/Addressing-Challenges-in-Reduced-Order-Modeling.aspx
Two Sandia scientists cited for computing advances yielding real world impact
Sandia scientists Ali Pinar (8962) and Cindy Phillips (1400) have been selected as distinguished members of the Association for Computing Machinery (ACM).
ACM, the world’s leading association of computing professionals, selected Ali and Cindy for their significant accomplishments and impact in computing. ACM recently selected 49 members for this recognition in the areas of education, engineering, and science.
Ali, a principal member of the technical staff, centers his work on applying graph algorithms to real-world problems. He has worked on combinatorial problems arising in parallel and scientific computing, electric power systems, and data, especially graph mining.
He first worked at Sandia as an intern in 1999 while he was working toward his PhD at University of Illinois at Urbana-Champaign. He received his bachelor’s degree in computer science from Bilkent University in Turkey and PhD in computer science from the University of Illinois. Since returning to Sandia full-time in 2008, he has focused on modeling and analysis of graphs and using sampling and streaming algorithms for massive data sets. This recent work has received three best paper prizes from the Society for Industrial and Applied Mathematics, ACM, and the Institute of Electrical and Electronics Engineers (IEEE).
Ali is a member of Society for Industrial and Applied Mathematics (SIAM), and IEEE. He is a member of the editorial boards of SIAM Journal on Scientific Computing, SIAM News, and Journal of Complex Networks. He has chaired five international meetings and served on more than 40 program committees.
Cindy, a senior scientist in Sandia’s Computing Research Center, conducts research in combinatorial optimization, algorithm design and analysis, and parallel computation. She has applied these techniques to many areas including scheduling, network and infrastructure surety, integer programming, graph algorithms, computational biology, quantum computing, computer security, wireless network management, social network analysis/graph data mining, sensor placement, and co-design of algorithms for next-generation architectures.
She received a bachelor’s degree in applied mathematics from Harvard University and a PhD in computer science from Massachusetts Institute of Technology. She has been at Sandia since 1990. Her papers on combinatorial scheduling, with academic co-authors, have influenced the real-time scheduling community. She was a member of a team that won an R&D 100 award in 2006 for supercomputer processor allocation and a member of a finalist team for the Edelman award in 2008 for sensor placement in municipal water networks.
Cindy has chaired seven major international meetings and served on more than 60 program committees. In particular, she has served on the program committee for at least 20 ACM conferences, including chairing its flagship parallel algorithms conference, the ACM Symposium on Parallelism in Algorithms and Architectures. She also served as a conference officer.
The distinguished members are selected from leading academic institutions and corporate and national research laboratories around the world. This year, ACM selected distinguished members from Argentina, Belgium, Canada, China, Egypt, Finland, Hong Kong, India, Japan, Portugal, Qatar, the United Kingdom, and the United States.

Ice sheet modeling of Greenland, Antarctica helps predict sea-level rise
http://www.sandia.gov/news/publications/labnews/articles/2016/05-02/ice_modeling.html
Data collection for the Transportation Security Administration
Data collection for the Transportation Security Administration
Recently, two projects for the Transportation Security Administration (TSA) have succeeded in collecting data from Transportation Security Officers (TSOs) that are, in many ways, unparalleled in the research community. These projects, Performance Decrement and Passenger Threat Detection Resolution (PTDR) were aimed at answering different questions for different duties at the checkpoint. As such, the methods for data collection were quite different.
The primary question in the Performance Decrement project had to do with how long TSOs can interrogate X-Ray images of passenger carryon items without a break before performance degrades. To address this question, we attempted to replicate the environment in which TSOs make these decisions as closely as possible. We created custom software that emulated the look and feel of the Rapiscan AT-2 systems located at checkpoint around the country, received over 1000 raw x-ray image files from TSA, and then captured 31 or 32 image products for each of those raw x-ray files using a Rapiscan emulator. We also wanted to understand how TSOs interrogated these images, so we integrated a 3-camera infrared eye tracking system into the emulator and we located the entire system at 6 checkpoints around the country over the course of 6 months (2 weeks per airport), collecting ~3 hours of data from 187 TSOs. This data collection resulted in over 80 million eye tracking data points and terabytes of human-emulator interaction data (image manipulation tool use, threat/no threat decisions, decision times).
The PTDR project was focused on identifying the characteristics of TSOs that are predictive of performance on the job in all checkpoint duties except the X-Ray. Thus, we are investigating whether any of 33 cognitive and personality measures (most normed and validated, two Sandia-created measures (touch aversion and Sandia Progressive Matrices)); such as the Big 5 personality traits, analogical reasoning, and perspective-taking; would predict TSO performance at the Travel Document Checker, the Divest Officer, the Dynamic TSO (who performs bag checks, pat-downs), the Advanced Imaging Technology, or the Walk-through Metal Detector duty stations. We collected over 1,000 responses on these measures from 385 TSOs at 8 different airports around the country using cellular iPads and Survey Monkey. This process took between 3.5 and 7.5 hours for each TSO to complete, and wound up totaling ~2200 man hours of TSO time. Data collection took approximately 6 months of calendar time. We are building statistical models relating their responses on these measures to performance metrics TSA collects about them including scores on practical skills examinations, knowledge of standard operating procedures, and (for divergent validity) scores on Threat Image Projections, which are an operational measure of X-Ray effectiveness.
Contributors to the success of these two projects (alphabetical order):
PI: Ann Speed
Glory Emmanuel Avina , Kristin Divis, Michael Haass, Mike Heister, Lauren Hund, Robert Kittinger, Kiran Lakkaraju, Jina Lee, Shanna McCartney, JT McClain, Monique Melendez, Kate Rodriguez, Fred Rothganger, Austin Silva, David Stracuzzi, Derek Trumbo, Michael Trumbo, Ed Vieth, and Christy Warrender, Andy Wilson
Advanced Release of Draft Technical Specifications for Crossroads
The first version of the draft technical specifications for Crossroads were released on November 1st 2015 to the vendor community for comment. Crossroads, one of two platforms targeted for delivery in 2020, will be the NNSA’s third Advanced Technology System. Crossroads will be the second platform procured as part of the Alliance for Application Performance at EXtreme Scale (APEX), a collaboration between Sandia National Laboratories, Los Alamos National Laboratory and Lawrence Berkeley Laboratory. Crossroads will be the third Advanced Technology System (ATS) since the NNSA merged their advanced technology and capability computing platform acquisition strategies. The Crossroads platform must balance the need to satisfy the NNSA’s mission while advancing technology on the path to exascale.
To maximize the impact Crossroads will have on the path to exascale, the procurement process was started a full five years prior to the target date for platform delivery, versus two to three years in prior procurements. Initiating interactions with technology providers in this timeframe has allowed the DOE to influence architectural directions of hardware, currently in the design phase, that will be available in the 2020 timeframe. Previous procurements have begun too late to have this opportunity for influencing hardware designs. In addition, the ATS program includes a significant amount of funding for non-recurring engineering. This enables the DOE to invest in targeted technologies that will enhance the performance of existing NNSA mission simulation codes and allow investigation and evaluation of future programming models and performance aspects of evolving hardware architectures on the path to exascale. The APEX team has established unprecedented communication channels with a wide range of technology providers of components that will potentially be included in the selected platform. Numerous face-to-face and regular, often bi-weekly, teleconferences have and continue to be conducted.
To maximize the impact of Crossroads, a different approach has been used in authoring the technical requirements. Due to the advanced nature of the procurement, the requirements are much less proscriptive than previous specifications. Part of the motivation for this approach is simply that many aspects of a system five years from now are impossible to accurately characterize. More importantly, the APEX design team wanted to leave as much room for technology innovation as possible in the process. As part of this change in procedure, APEX has released a document that describes NNSA and Office of Science workflows, basically how we use these massive resources. Through this document we are communicating with the vendor our mission, what we want to do, so that the vendor can construct a response using their technology that they feel will best achieve our goals. This document also provides a conduit for conversation that we are confident will also lead to the best possible platform in the 2020 time frame. Additional focus areas have been added to the technical specifications with the goal of taking advantage of emerging advanced technologies that the potential to positively impact platform efficiency.


Trinity
The next-generation Trinity supercomputing platform project has recently achieved two important milestones. Trinity is an advanced computing platform for stockpile stewardship that is being architected and procured by the Alliance for Computing at Extreme Scale (ACES), a partnership between Sandia and Los Alamos National Laboratories, under the NNSA Advanced Simulation and Computing (ASC) Program. The first phase of Trinity was delivered and installed at Los Alamos in Fall 2015, and at the end of November 2015, the ASC Level 2 Milestone for Trinity System Integration Readiness of the Phase 1 system was successfully completed. The Phase 1 system consists of compute nodes based on Intel Haswell processors, whereas the Phase 2 system will be based around Intel Phi (Knights Landing) many-core processors. Following the delivery and integration of Trinity Phase 1, acceptance testing and performance assessment was completed in December 2015, leading to formal acceptance of the Phase 1 system before the end of 2015. Importantly, the system performance exceeded the procurement requirement by more than 25%, as measured by a sustained system performance metric of 516 (relative to 400 required) based on representative proxy applications. The next steps for Trinity will be further user testing of Phase 1 during an open science period, followed by initiation of stockpile computing campaign work, and delivery of the Phase 2 system later in fiscal year 2016.
A new, optimization-based coupling strategy for nonlocal and local diffusion models
The use of nonlocal models in science and engineering applications has been steadily increasing over the past decade. The ability of nonlocal theories to accurately capture effects that are difficult or impossible to represent by local partial differential equation (PDE) models motivates and drives the interest in a wide range of alternative nonlocal models. For instance, nonlocal continuum theories such as peridynamics or physics-based nonlocal elasticity allow interactions at distance without contact and can accurately resolve small scale features such as crack tips and dislocations. However, the improved accuracy of nonlocal models comes at the price of a significant increase in computational costs compared to, e.g., traditional PDEs. In particular, a complete nonlocal simulation remains computationally untenable for many science and engineering applications. Further, nonlocal models generally require the application of volume constraints, which are more difficult to specify in practice than the boundary conditions of the local theory. As a result, many researches have focused attention on the development of various Local-to-Nonlocal coupling strategies, which aim to combine the accuracy of nonlocal models with the computational efficiency of PDEs. The basic idea is to use the more efficient PDE model everywhere except in those parts of the domain that require the improved accuracy of the nonlocal model.
Sandia researchers have recently developed a new, optimization-based method for the coupling of nonlocal and local diffusion problems. The approach formulates the coupling as a control problem where the states are the solutions of the nonlocal and local equations, the objective is to minimize their mismatch on the overlap of the nonlocal and local domains, and the controls are virtual volume constraints and boundary conditions. The new coupling approach is supported by rigorous mathematical theory establishing the well-posedness of the optimization formulation. Sandia researchers have implemented and demonstrated the optimization coupling approach using Sandia’s agile software components toolkit; the latter provides the groundwork for the development of engineering analysis tools.

Ryan Grant Wins Best Paper Award at IEEE Cluster Conference
The Best Paper Award at the 2015 IEEE International Conference on Cluster Computing was given to a paper entitled “Optimizing Explicit Hydrodynamics for Power, Energy, and Performance” co-authored by Ryan Grant and colleagues from Lawrence Livermore National Laboratory. The paper was selected from 38 regular papers presented at the conference.
Ryan Grant is an SMTS in the Scalable System Software Department. He graduated with a PhD in Computer Engineering from Queen’s University in Kingston, Ontario, Canada in 2012. His research interests are in high performance computing, with emphasis on high performance networking for exascale systems. Ryan currently leads the Portals interconnect programming interface research team.
More information on the 2015 IEEE International Conference on Cluster Computing can be found on this site:
press3.mcs.anl.gov/ieeecluster2015/

New Exascale Interconnect Based on Sandia Technology
French Supercomputer vendor Atos, formerly Bull, recently announced plans to develop a new interconnect for exascale computing systems based on Sandia’s Portals 4 network programming interface. A keynote talk at the recent IEEE Symposium on High-Performance Interconnects entitled “The BXI Interconnect Architecture” detailed the design of the network interface and switch hardware that comprise the interconnect. The network interface is designed specifically to implement the semantics of the Portals 4 interface, including completely offloading several features, such as MPI tag matching.
The abstract and slides from the keynote talk are available at the following site:
Kurt Ferreira Receives IEEE Early Career Award
Kurt Ferreira has been selected to receive the 2015 IEEE Technical Committee on Scalable Computing Award for Excellence for Early Career Researchers. The award will be presented during the Award Ceremony at the IEEE/ACM International Conference on High Performance Computing, Networking, Storage, and Analysis (SC’15) in Austin, Texas, in November. This award recognizes up to three individuals who have made outstanding, influential, and potentially long-lasting contributions in the field of scalable computing within five years of receiving their PhD degree.
Kurt is a PMTS in the Scalable System Software Department (1423). His research interests include the design and construction of operating systems and runtimes for massively parallel systems and innovative application and system-level fault-tolerance mechanisms. Kurt received his BS in mathematics and BS in computer science in 2000 from New Mexico Tech and his MS in computer science in 2008 and PhD in computer science in 2011 from the University of New Mexico. In addition to his position at Sandia, Kurt also holds a Research Associate Professor appointment in the Department of Computer Science at the University of New Mexico.
More information on the award can be found at the following site:

Stewart Silling received the 2015 Beltyschko Medal
Stewart Silling was recognized for outstanding and sustained contribution to the field of computational mechanics For developing and demonstrating peridynamics as a new mechanic methodology for modeling fracture and high strain deformation in solids at the Annual Meeting of the US Association for Computational Mechanics in San Diego in July 2015.


Pavel Bochev receives DOE’s E.O. Lawrence Award
Pavel Bochev (1442), a computational mathematician, has received an Ernest Orlando Lawrence Award for his pioneering theoretical and practical advances in numerical methods for partial differential equations.
“This is the most prestigious mid-career honor that the Department of Energy awards,” says Bruce Hendrickson (director 1400, Computing Research).
Lawrence Award recipients in nine categories of science each will receive a medal and a $20,000 honorarium at a ceremony in Washington, D.C., later this year.
In the category “Computer, Information, and Knowledge Sciences,” Pavel’s work was cited for “invention, analysis, and applications of new algorithms, as well as the mathematical models to which they apply.”
Says Pavel, “I am deeply honored to receive this award, which is a testament to the exceptional research opportunities provided by Sandia and DOE. Since joining Sandia I’ve been very fortunate to interact with an outstanding group of researchers who stimulated and supported my work. These interactions, as well as funding from the Advanced Scientific Computing Research Program of DOE’s Office of Science and the ASC program of the National Nuclear Security Administration, helped shape, grow, and mature the research effort leading to this recognition.”
Said Energy Secretary Ernest Moniz, “I congratulate the winners, thank them for their work on behalf of the department and the nation, and look forward to their continued excellent achievement.”
The Lawrence Award was established to honor the memory of Ernest Orlando Lawrence, who invented the cyclotron — an accelerator of subatomic particles — and received a 1939 Nobel Prize in physics for that achievement. Lawrence later played a leading role in establishing the US system of national laboratories.
The most recent prior Sandia recipient of the Lawrence Award is Fellow Jeff Brinker, who received the honor in 2002.
Sandia-led Mantevo Project Wins 2013 R&D 100 Award
The Sandia-led Mantevo Project for developing miniapps and related application proxies that enable design space exploration for next generation computer systems and application designs received a 2013 R&D 100 award.
DOE-Micron Hybrid Memory Cube Research, Development, and Analysis
On July 17, 2014 representatives from Sandia, LBNL, PNNL, and DoD’s LPS/ACS organizations met with Micron to discuss the Multi-FPGA application development environment, and the status of memory controller updates for the Micron hybrid memory cube (HMC) test and evaluation (T&E) boards. Initial Micron testing demonstrated approximately an order of magnitude improvement in performance on the giga updates per second (GUPS) benchmark using the HMC memory versus third generation, conventional dual data rate (DDR3) memory. After initial testing of these prototypes by Micron, eight test and evaluation boards were produced under a Sandia contract for DOE—for both the ASC and ASCR program offices. A DS&A WFO program subsequently order two additional T&E boards. Micron presented NDA information for integration of HMC technology into compute node designs. Sandia, LBNL, PNNL and LPS/ ACS agreed to share lessons learned and documents to help each other develop application tests and benchmarks among our group.
On July 18, 2014 Sandia held a kickoff meeting at Micron for new DOE ASC and ASCR R&D project. This project is focused on three design studies based on HMC technology. The first two design studies are focused on system R&D for functions in memory cubes, and for integration of cubes into resilient memory modules. The third design study is focused on an analysis of search operations in a HMC or HMC module. To support this R&D, Micron is also designing and producing two additional T&E boards, a small board with a single FPGA and a single HMC for application development, and a board with two HMCs and two FPGAs that is designed for analysis of chaining and module integration protocols. Sandia provided advice to Micron on the specific R&D topics that would have the greatest potential impact for HMC in DOE systems.

Evaluating the impact of SDC on the GMRES iterative solver
Accepted to the 28th IEEE International Parallel and Distributed Processing Symposium (IPDPS), May 2014.
Coupling Local to Nonlocal Continuum Models
Nonlocality, the incorporation of a length scale within the equations of mechanics, is increasingly recognized as an essential aspect of high-fidelity modeling of the fracture and failure of solids. The nonlocal peridynamic model, while providing the key advantage of unguided, autonomous crack growth, is computationally slower than the local finite element method, motivating the search for an accurate local-nonlocal coupling algorithm. Recently, under the LDRD project Strong Local-Nonlocal Coupling for Integrated Fracture Modeling, our team discovered a way to vary the length scale in different parts of a structure between zero (local) and positive (nonlocal) values seamlessly, minimizing artifacts and errors within the transition region.
Our approach is unique in that it is contained within the continuum, rather than discretized, mathematical system. As a continuum method, its advantages immediately carry over to any suitable discretization scheme or software that accurately solves the continuum equations. The method, which appears to be applicable to 3D and to nonlinear material response, promises to provide a mathematical tool for accurately and efficiently modeling the damage and fracture of complex solids and structures under dynamic loading.
The figure below illustrates the absence of artifacts using the new method. The graph shows the predicted strain field in the stretching of a 1D elastic bar. The bar is partitioned into local and nonlocal subregions. With the new coupling method, there is zero error in the transition regions between local and nonlocal equations for this particular example problem.
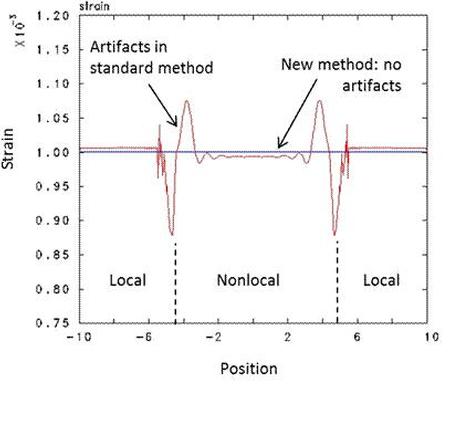
2013 Dakota releases provide users an array of new features
Dakota version 5.3, released 1/31/2013, and its partner version 5.3.1, released 5/15/2013, feature new adaptive, sparse, and surrogate-based UQ methods, new Bayesian calibration methods, and improvements to discrete optimization. The new versions also include enhancements to the testing infrastructure, core framework, and portability (including to native Windows). The Dakota user experience continues to improve through the Dakota GUI (named JAGUAR); formal release of JAGUAR version 3.0 is scheduled for June 2013. Dakota version 5.3.1 includes revamped getting-started, tutorial, and examples in the user’s manual. Version 5.3.1 is the first of Dakota’s new semiannual releases, with future deployments scheduled for May and November of each year.
Checkpoint Compression – An Application Transparent Performance Optimization
Checkpoint/restart is the prevailing approach for application fault-tolerance for large-scale systems. With the largest HPC systems already consisting of millions of cores, we expect HPC system core counts to continue to increase. In these large-scale environments, a confluence of issues including extremely low system MTBF and increased I/O pressures has raised concerns about the continued viability of checkpoint/restart-based fault tolerance. The size of an applications checkpoint is the key driving factor in checkpoint/restart performance. To minimize the size of checkpoints volumes, we have developed a library that uses readily available compression algorithms to transparently compress application checkpoints on the fly. Using this library on a number of key DOE simulation workloads, we show that this method can greatly increase the viability of checkpoint restart for current and future systems. Figure 1 shows the application efficiency (percentage of application run time performing useful work) of this compression technique in comparison with traditional (labeled “baseline”) and an optimal incremental checkpointing approach. We see this method significantly outperforms an incremental checkpointing approach, with optimal performance occurring combining both incremental and checkpoint compression.
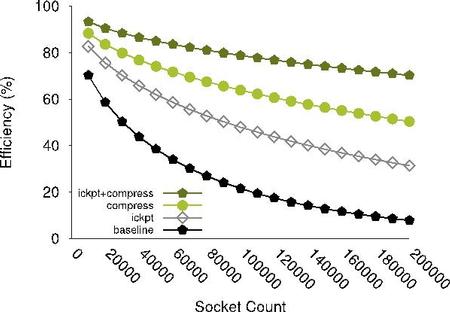
ACES and NERSC form partnership for next-generation supercomputers, an unprecedented collaboration between NNSA and the Office of Science
The Alliance for Computing at Extreme Scale (ACES, a collaboration of the NNSA’s Los Alamos National Laboratory and Sandia National Laboratories) and the Office of Science’s National Energy Research Scientific Computing Center (NERSC) have fully integrated as a team as they work towards their respective next-generation supercomputer deployments. The goal of the new alliance is to acquire two supercomputers, Trinity and NERSC-8, using a common set of technical requirements and a single procurement process. The advantages of the combined acquisition strategy includes: strengthening the partnership of the NNSA and The Office of Science (SC) in the area of high-performance computing, leverage shared technical and risk management expertise, save industry time and money in responding to a single RFP and a single set of requirements, and the benefits associated with shared experiences in production operations.
PANTHER Grand Challenge LDRD Kicks Off
The PANTHER (Pattern ANalytics To support High-performance Exploitation and Reasoning) Grand Challenge officially kicked off on October 1st. This represents an enormous laboratory investment in a project that will represent a new level of integrating capabilities in 1400 and 5000 to bring solutions to some of the most important problems facing the current generation of remote sensing platforms. PANTHER will advance the science of remote sensing to exploit critical patterns and relationships in high-volume, pixel-based national decision systems. These systems detect the subtlest of features, including spatially and temporally distributed cues associated with gradually unfolding events. However, by focusing on pixels, current exploitation infrastructure enables only a fraction of sensors’ full potential − in sensitivity, specificity, and magnitude. Furthermore, this paradigm does not scale to the increase in pixel-based data volumes anticipated in coming decades. To maximize remote sensing capability, scientific advances are required across three key technical domains: Sensor Exploitation, where innovative algorithms extract and characterize relevant entities from raw data streams in real time; Discrete Analytics, where semantic graphs and tensors represent, index, and correlate entities, enabling complex spatiotemporal queries; and Human Analytics, where empirical studies of visual cognition inform technologies that support rapid, data-based situational assessment via pattern-based content query, retrieval, hypothesis formation, and testing.
Extreme Scale Algorithms and Solvers Resilience (EASIR) Research Funded by Office of Science
The Office of Science has funded a new effort jointly lead by Sandia National Laboratories (SNL) and Oak Ridge National Laboratories (ORNL) to explore scalable algorithms for the next generation of hardware architectures. As DOE moves towards the Leadership-class machines of the next 5-10 years, algorithms are going to face significant challenges due to: extreme concurrency, complex memory hierarchies, costly data movement, a steep rise in fault rates, and heterogeneous processor architectures. In the face of these challenges, major innovations in algorithm design will be required just to achieve acceptable productivity on future DOE Leadership computers, let alone realize their full promise. The resulting solver algorithms will provide a breakthrough in state-of-the-art algorithm design for the next generation of high-performance computers, providing support for hybrid systems, and significantly exceeding the performance of currently available solutions. This project is an outgrowth of a three year Office of Science funded Math/CS Institute project started in 2009. This project will be funded for three years and includes collaboration with three universities: University of Illinois, University of California, and University of Tennessee.
New Umbrella CRADA with Caterpillar Approved
A new Umbrella CRADA with Caterpillar Inc. has been formally approved. This collaboration will bring together Sandia’s broad, advanced simulation technology for addressing Caterpillar’s multi-faceted design, analysis, and decision-making challenges. In turn, the development and integration of Sandia’s foundational technologies across these areas will be greatly accelerated. Moreover, the collaboration will further Sandia’s mission to meet the nation’s energy and economic security challenges and provide Caterpillar with advanced technical capabilities for improved decision making and virtual product development. The CRADA covers broad areas of computer and computational science, information and data analysis, engineering science, and high-performance computing. In addition to the Umbrella CRADA, a Project Task Statement (PTS) was also approved and work has already begun. The PTS supports improvements to the DAKOTA optimization and uncertainty quantification toolkit, along with the initiation of work to make DAKOTA more interoperable with the Pyomo collection of algebraic optimization tools. These new capabilities will provide immediate benefits to Caterpillar and set the stage for more advanced optimization capabilities in the future. The PTS also provides for in-depth training and technical support of DAKOTA and Pyomo for Caterpillar.